
Mi van a müzlisdobozon?
A müzlisdobozon különböző feliratok vannak, melyek a müzli elkészítésének módjáról, összetevőiről tájékoztatnak. Izgalmas dolog összehasonlítgatni a különböző nyelvű feliratokat, az első lépés azonban a nyelvek azonosítása lenne. Ez azonban nem mindig könnyű.
Akik már a negyven felé közelednek, emlékezhetnek azokra az időkre, amikor irigykedve néztünk egy „nyugati” dezodort vagy egy a Mariahilferstraßén beszerzett mikrohullámú sütő dobozát, hogy a görögtől a svédig milyen sok nyelven találunk rajta feliratokat. Abban persze nem reménykedhettünk, hogy lengyel vagy bolgár feliratot is találunk.
Azóta szerencsére sokat változott a világ, és egy doboz mosópor megvásárlásának köszönhetően nem csak a ruhánk lehet tiszta, hanem néhány percet eltölthetünk olyan játékokkal, mint hogy mérlegeljük, hogy jobban hasonlít-e a cseh a szlovákra, mint a szlovén a horvátra, vagy éppen mennyire hasonlít egymásra a lett és a litván. Ha szerencsénk van, a szöveg mellett fel van tüntetve (például az autókról ismert jelzések segítségével), hogy milyen nyelvű az adott szöveg – nincs azonban mindig ekkora szerencsénk. Az alábbiakban egy olyan módszert mutatunk be, mely segítségével könnyen megkülönböztethetjük régiónk nyelveit anélkül, hogy bármelyiken is akár egy szót tudnánk.
A módszer lényege, hogy szinte minden nyelv ábécéjében vannak olyan betűk, amelyek sehol máshol nem fordulnak elő. Ilyen például a magyarban az ő és az ű: ha egy külföldi ilyet lát, biztos lehet benne, hogy magyar szövegről van szó. A még a ˝ mellékjel is nagyon ritka más nyelvekben: a (La)TeXben is a \H paranccsal lehet feltenni a betűkre: a H a Hungarian rövidítése. A latin betűs írásokban egyedül a feröeri használja az ő-t időnként az ø helyett, a cirill írású nyelvekben pedig a csuvasban használatos az ӳ az [ü] jelölésére.

(Forrás: Wikimedia Commons / Mulder1982 / CC bY 3.0)
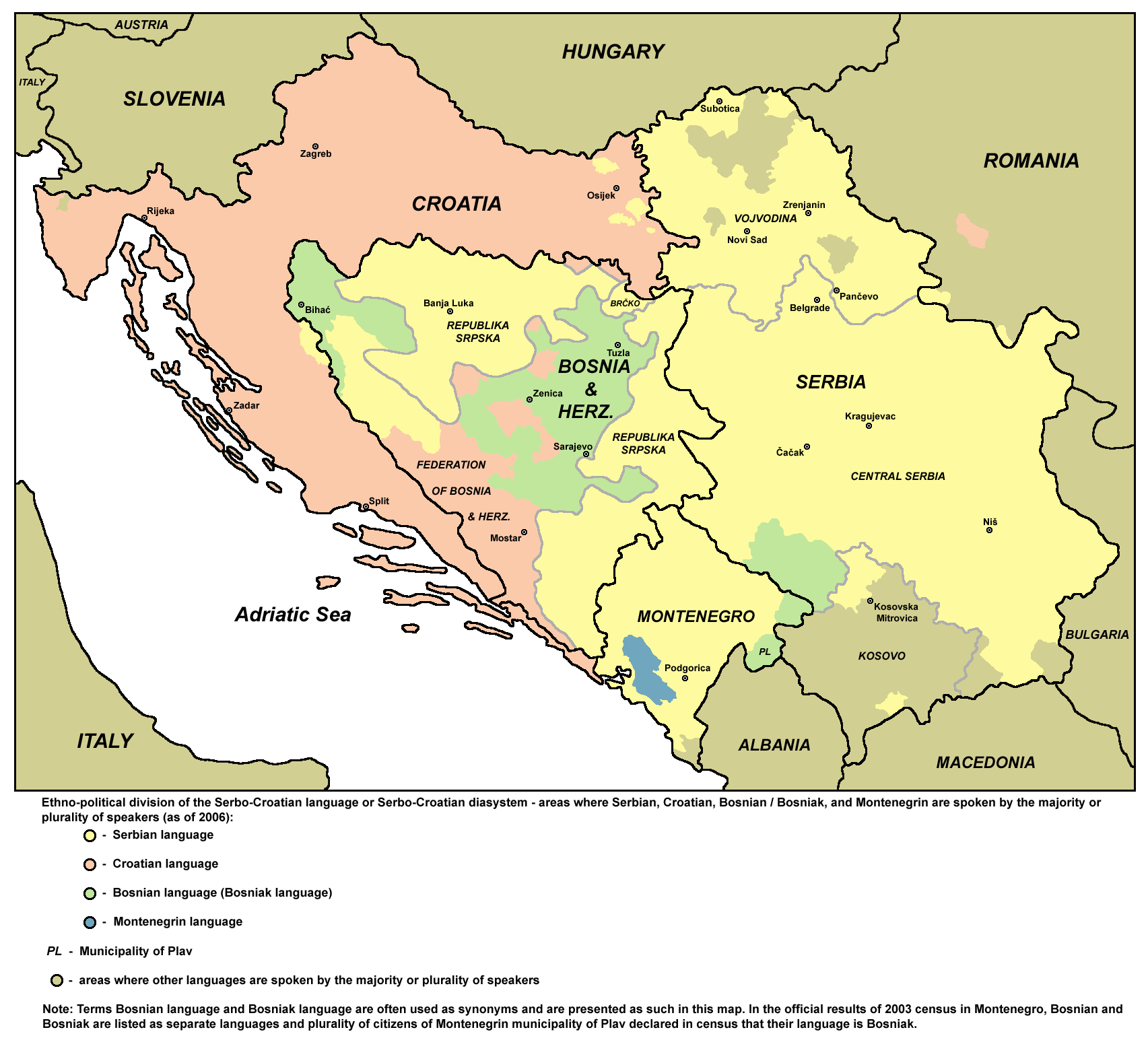
Hasonló módszerrel azonosíthatjuk a Balti-tenger és a Balkán-hegység közötti összes nyelvet. Cikkünkben kizárólag a latin betűs nyelvekkel foglalkozunk (ezek ugyanis egyértelműen elkülöníthetőek a más írással írt nyelvektől), és kizárólag ezek egymástól való megkülönböztetésének lehetőségét vizsgáljuk. Nem foglalkozunk a kisebbségi nyelvekkel, mert ezekkel legfeljebb elvétve találkozhatunk. A vizsgált nyelvek a következők: észt, lett, litván, lengyel, cseh, szlovák, horvát, szlovén, román, albán. Nem foglalkozunk azzal, hogy az említett betűket hogyan kell kiolvasni. Természetesen a módszer csak akkor működik, ha a feliratok a hivatalos (illetve általánosan alkalmazott) helyesírásoknak megfelelnek. Arra is fontos emlékezni, hogy ez a módszer inkább csak hosszabb szövegeken alkalmazható, ahol nagy valószínűséggel már előfordul minden betű. Ha valamelyik betűt nem látjuk, az nem feltétlenül jelenti, hogy nem az adott nyelvről van szó.

(Forrás: Wikimedia Commons / Alnatura / CC BY-SA 2.0)
A Balti-tenger partján
Az észtet egyetlen betűjéről lehet azonosítani, az õ-ről. Ez egy o, melynek a tetején hullámvonal (tilde) található, de ezt néhány karakterkészletben kisebb méretben nehéz megkülönböztetni a vízszintes vonaltól (makron). Ez a betű egyébként egyértelműen megkülönböztetni az észtet a finntől is, melyhez egyébként írásképe igen hasonló. (Bár a régióban egyedülálló az õ, távolabb előfordul, például a portugálban.) Egy másik különbség az észt és a finn között, hogy a finn nem használja az ü-t, az észt pedig az y-t. Mind a finnre, mind az észtre jellemző még az egymást követő azonos magánhangzójelek sorozata, de az első szótagi ee, oo és öö inkább az észtre jellemző, a nem első szótagi bármilyen duplázás pedig inkább a finnre (bár kivételek lehetnek).
A lett már egy sor fogódzót nyújt, mert két olyan mellékjelet is használ, amely más nyelvekben ritkán fordul elő, Európában pedig sehol máshol. Az egyik a betű feletti vízszintes vonás (ā, ē, ī, ū – ez utóbbi azonban előfordul a litvánban is!), a másik pedig a betű alatti, bizonyos betűtípusoknál kampószerű, másoknál egyenes vessző (ķ, ļ, ņ). Tulajdonképpen ez utóbbinak egy variánsa a ģ: itt a g lenyúló szára miatt kerül a mellékjel a betű fölé – a nagybetűk esetében azonban ennél is a betű alatt van: Ģ. Ezen kívül találunk a lettben más mellékjeles betűket is (č, š, ž), de amint látni fogjuk, ezek sok más ábécében előfordulnak még – így például a litvánban.
A litván íráskép szempontjából a lett és a lengyel keveréke: ha a lengyelből ismert ą-t és ę-t č-vel, š-sel vagy ž-vel keverve látjuk, biztosak lehetünk benne, hogy litván felirattal van dolgunk. Azért vannak olyan betűk is, amelyek egyértelműen azonosítják a litvánt: az ė az į és az ų.
Láthatjuk tehát, hogy az olyan tipikusan lengyelnek ismert betűk, mint az ą és az ę nem azonosítják egyértelműen a nyelvet, hiszen előfordulnak a litvánban is. Szerencsére vannak még a lengyel ábécében olyan betűk, melyek máshol nem fordulnak elő: ł, ś, ź, ż. A sajátos betűkön kívül a lengyel bővelkedik olyan betűkapcsolatokban, melyek könnyen felismerhetővé tehetik a nyelvet: cz, sz, rz. (A sz persze a magyarban is gyakori, de aki ezt a cikket el tudja olvasni, az meg tudja különböztetni a magyart a lengyeltől.) Sajátos vonása a lengyelnek a w használata és a v kerülése: míg a régió nyelveinek helyesírásában a w csak idegen szavakban használatos, addig a lengyelben ez általános (a w még önálló szóként is előfordul!), és a v használata a kivételes. Ennek – illetve az említett betűkapcsolatoknak – köszönhetően a lengyel még akkor is könnyen felismerhető, ha csak az angol ábécé betűit használták a szöveg írásakor.

(Forrás: Wikiemdia Commons / Maxxii / GNU-FDL 1.2)
Szláv szomszédságunk
A szlovák, a horvát és a szlovén helyesírás a cseh hatására fejlődött, ennek köszönhetően mindegyikben megvan a č, a š és a ž – mint láttuk, ezek a lett és litván helyesírásba is bekerültek. Szerencsére a négy helyesírás a hasonlóságok ellenére megkülönböztethető.
Csak a csehben fordulnak elő a következő betűk: ě, ř, ů. Csak a szlovákban fordulnak elő: ľ, ĺ, ŕ, ô. A szlovák felismeréséhez segítség lehet az ä is, mely a régióban a szlovákon kívül csak az észtben fordul elő.

(Forrás: Wikimedia Commons / Peter Zelizňák / GNU-FDL 1.2)
A csehet és a szlovákot megkülönbözteti a horváttól és a szlovéntől az is, hogy a magánhangzók jeleire – a magyarhoz hasonlóan – vessző kerülhet: á, é, í, ó, ú (vigyázat, nyelvészeti célú lejegyzésekben ezek előfordulnak a horvát vagy szlovén szövegekben is!) – ide tartozik a magyar szemmel furcsa ý is. Szintén e két nyelvben használatos jel a ň is.
Csak a horvátban fordul elő a đ (Đ). A csehtől, szlováktól, szlovéntól jól megkülönbözteti a ć is – ez ugyan megvan a lengyelben, de a lengyel írás jelentősen eltérő képének köszönhetően elég jó azonosító jegyként használható. Ezeken kívül a horvát azonosítását segítik a lj és nj betűkapcsolatok: ezek a csehben, a szlovákban és a szlovénben lengyelben nem fordulnak elő (a nj azonban az albánban sem ritka). (A montenegróiban használatos a lengyelnél említett ś és ź is, de jelen pillanatban még nem jellemző, hogy montenegrói szöveggel találkozzunk. A bosnyák helyesírás viszont teljesen megegyezik a horváttal.)
(Forrás: Wikimedia Commons / PANONIAN, Kwamikagami)
A szlovén a módszerünk Achilles-sarka, ugyanis a szlovén helyesírásban nincs egyetlen olyan betű sem, mely ne fordulna elő valamelyik másik ábécében. Ha tehát a szövegünk elég hosszú, de a č-n, az š-en és a ž-n kívül nem fordul elő benne egyik a csehre, a szlovákra vagy a horvátra jellemző betű sem, akkor megalapozott a gyanú, hogy szlovén szövegről van szó.
A Balkán
A román ismét elkényeztet bennünket, mert szintén több olyan betűt is használ, melyet sehol a környéken nem találunk meg. Ezek: ă, â, î, ș és ț. Az utóbbi két betű alatt vessző van, nem pedig cedilla (horgas farkinca), azaz nem ş, ill. ţ. A különbség nem minden karakterkészlet esetében nyilvánvaló: elvben a vesszőnek nem lenne szabad hozzáérnie a betű testéhez – ezzel szemben a cedillának a betű testéből kellene kiindulnia.
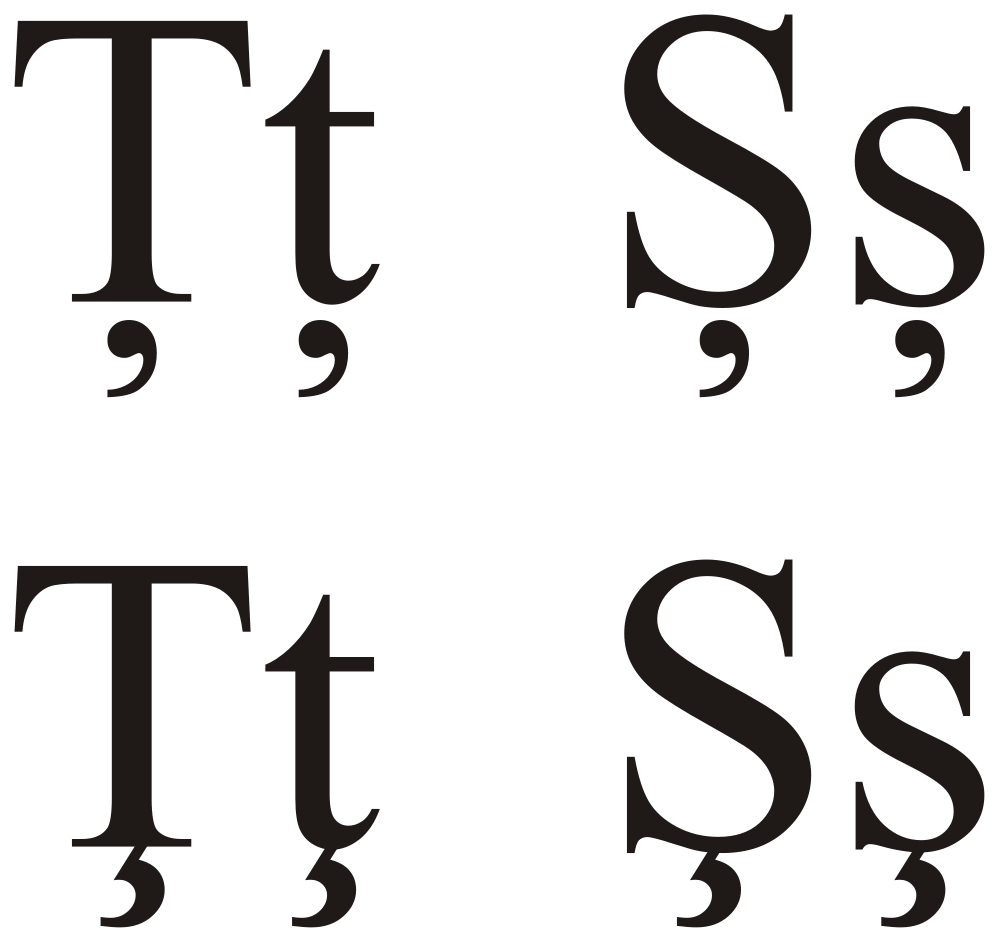
(Forrás: Wikimedia Commons / AdiJapan / GNU-FDL 1.2)
A valóságban azonban gyakran cedillás változatokkal találkozunk.
Az albánban mindössze két olyan betűt találunk, amely a régióban egyedülállónak számít: a ç-t (cedillával) és az ë-t. Ez utóbbi különösen gyakori. Feltűnő lehet még a q gyakorisága: a régió más nyelveiben ezt csak ritkán, idegen szavakban használják, az albánban azonban saját szavakban is, így viszonylag gyakran bukkan fel. Feltűnőek még a ll, rr, dh, sh, th, xh, zh, gj és nj betűkapcsolatok, melyek a régió más nyelveiben nem jelennek meg hasonló gyakorisággal (kivéve a már említett horvát-szlovén nj-t).
A valóságban persze a különböző nyelvű szövegek írásképe sokkal bonyolultabb módon különbözik, nem csupán abban, hogy milyen betűk fordulnak vagy nem fordulnak benne elő. A nyelveket azonosító számítógépes eljárások nem is ilyen módszerekkel dolgoznak, hanem statisztikai alapon: azt figyelik, milyen betűk milyen valószínűséggel követik egymást.
Kapcsolódó tartalmak:
Hasonló tartalmak:
Hozzászólások (20):
Követem a cikkhozzászólásokat (RSS)Az összes hozzászólás megjelenítése
@LvT: „éppen a Nyestről tudhatjuk, hogy hamarabb volt Magyarországon futball, mint magyar futballterminológia.” Ez nagyon erős csúsztatás. Futballterminológia nélkül nem volt futball. Más kérdés, hogy később ezt a terminológiát lecserélték.
„Egyrészt ilyen forrással még nem találkoztam.” Én idéztem be Máchektől. Továbbá a szó a latinban görög átvétel, márpedig az eredeti görög g j-vé vált.
„A cseh is olyan, hogy a nyelvújítás eltávolította az irodalmi nyelvet a beszélt nyelvtől a környéken az egyik legnagyobb mértékben.” Ha ez ilyen egyszerű lenne, akkor az anděl helyett angelt találnánk.
„ezt szignifikánsan nem haladja meg a <nj> betűkapcsolatot tartalmazó, müzlisdobozra felkerülő horvát szavak frekvenciáját” :DDD Akkor kérnék egy kísérletet. Vegyünk bármilyen párhuzamos cseh és horvát szöveget, és annak mondjuk egy kb. egyoldalas részletét. Mai legyen, adok annyi előnyt, hogy a témája, stílusa szabadon választható. Szeretném tudni, milyen az nj-k aránya a két szövegben.
„mert az annyira intelligens olvasó ezzel már tisztában lehetett” Asszem, nagyon sok embert sértődik meg jogosan, ha azt állítják, hogy nem intelligens, ha kapásból nem tudja megkülönböztetni a cseh és a szlovák szöveget...
A maláj példát egyáltalán nem értem. Maláj szavak akkor fordulhatnak elő közép-európai nyelvekben, ha azok nemzetközi szóvá váltak. Akkor pedig jó eséllyel felismerhetőek – hacsak nem adaptálódtak erősen a befogadó nyelvbe: ekkor viszont helyesírásuk is igazodni szokott az adott nyelv szabályaihoz.
chasa-valtice.cz/wp-content/uploads/2010/09/pisnicky2.pdf Na most ez nagyon nem fair húzás. A belinkelt szövegről üvölt, hogy nyelvjárási, ráadásul szinte szlovák: a nőnemű melléknév egyes tárgyesetű alakja - ou helyett -ú, a visszaható névmás se helyett sa, az sg. 1. birtokos melléknév hímnemű alakja můj. Az is feltűnő, hogy egy sorban rögtön két g-s szó van, ami ugye a csehre kevéssé jellemző. A galánka szót nem ismertem, rákerestem, csupa olyan oldalon bukkan elő, melyben a csehek a népdalokból ismert, de egyébként nem használt szavakat tárgyalják. Ráadásul igen hamar ezt találtam:
galánka = girlfriend
this is actually a Slovak word and it means a young girl. If the girl is connected with a particualr person within the context (i.e. 'moja galánka'), it may indeed mean a girfriend. (www.phrasebase.com/archive/czech/61-czech-vocab.html) A ligotat sa-ra rákeresve pedig csupa szlovák szótár bukkan elő. És akkor nézzük meg, honnan is van a dal: en.wikipedia.org/wiki/Valtice Meglepő-e, ha egy olyan cseh nyelvjárásban, mely erős átmenetet mutat a szlovák felé, és fő hangtani és lexikai vonásaiban közelebb áll a szlovák, mint a cseh irodalmi nyelvhez, az ’angyal’ szó alakjában is inkább szlovákos, mint csehes vonást mutat?
Egyébként azért is övön aluli a példa, mert a csehben a ě három dolgot jelölhet:
1. p, b, v után a [je] hangkapcsolatot,
2. m után a [nye] hangkapcsolatot,
3. d, t, n után azt, hogy a mássalhangzó [gy]-ként, [ty]-ként, illetve [ny]-ként ejtendő.
Ha nyelvjárási szövegben máshol fordulna elő, akkor is nagyjából ki lehetne találni, hogy pl. a kě a [kje] hangkapcsolatot jelöli, vagy a sě a [szje] hangkapcsolatot, esetleg azt, hogy az e előtt az [sz] lágy. A j utáni ě-nek viszont nincs értelme.
„<anjel>irodalmi szövegben is” Ismét hatalmas csúsztatás. Ez egy 1836-os szöveg: cs.wikipedia.org/wiki/M%C3%A1j_%28Karel_Hynek_M%C3%A1cha%29 Ugyanabból az évből származik, mint Vörösmarty Szózata. Erre hivatkozni olyan, mintha azt mondanánk, hogy a mai magyar nyelv részei (azaz egy müzlisdobozon is előfordulhatnak) az olyan alakok, mint a küzdtenek, hordozák, elhulltanak, éltet ’életet’, onta, keservben, jőni, epedez, ajakán, elbukál stb.
Ha már nyomtatott irodalmi szövegről van szó, hivatkozni lehetett volna ugyane szöveg első kiadására, ahol pl. a költemény első sora betűről betűre a következő: „Byl pozdnj wečer – prwnj mág –” Ez nem csak azt bizonyítaná, hogy nyomtatott cseh irodalmi szövegben – azaz akár egy müzlisdobozon is, ugyebár –, sűrűn előfordul a nj betűkapcsolat, hanem azt is, hogy a cikk állításával szemben a cseh helyesírásban is a w dominál a v helyett. Ezzel végérvényesen le lehetett volna leplezni, hogy a cikk egyedüli célja az olvasók megtévesztése.
Összefoglalva: olvasónk helyesen mutatott rá, hogy mai szlovák irodalmi szövegben előfordulhat az nj betűkapcsolat – erre két példát tudott hozni. Ugyanezen példák azonban nem érvényesek a cseh esetében. Olvasónk ahelyett, hogy elismerte volna, hogy példái a cseh esetében nem jók, azt próbálta meg igazolni, hogy a szlovák szavak cseh jövevények. E mellett döntő érveket nem tudott hozni, de természetesen ezt a forgatókönyvet sem zárhatjuk ki – ugyanakkor más megoldások is elképzelhetőek. Pillanatnyilag azonban olvasónk arra törekszik, hogy bizonyítsa, hogy az általa idézett szlovák alakok a mai cseh irodalmi nyelvben is előfordulhatnak. Igazának bizonyítása érdekében nem által cinkelt lapokat elővenni: nyelvjárási és archaikus szövegeket idéz úgy, mintha azok a ami irodalmi nyelv (illetve egy müzlisdoboz) szempontjából relevánsak lennének. Természetesen hihetnénk, hogy naivan ütközik bele az adatokba, és tudatlanságból értelmezi félre őket: hozzászólásaiból azonban nyilvánvaló, hogy meglehetősen tájékozott szlavisztikai kérdésekben, tehát nem téved hanem tudatosan manipulál. Célja már nem az, hogy kiderítse, hogy az adott kritérium mennyire használható, hanem az, hogy a cikk hitelét rontsa. Erről a pontról pedig már nagyon nehéz tisztán szakmai eszmecserét folytatni.
@LvT: Hogy összegezzem, az előbb belinkeltem két szemelvény után hol tartunk: önellentmondáshoz vezettek a cikk szabályai, amely cikk azt ígéri, hogy „könnyen megkülönböztethetjük régiónk nyelveit anélkül, hogy bármelyiken is akár egy szót tudnánk”, tehát a cikkbeli ökölszabályokon kívül más tudást nem használhatunk.
A cikk szerint „[c]sak a csehben fordulnak elő a következő betűk: ě, ř, ů.” És ezek szerint a szemelvények csak cseh nyelvűek lehetnek, mert ilyenek előfordulnak benne. De mégsem lehet cseh, mert „nj betűkapcsolat[…] a csehben […] nem fordul[] elő”., mert <nj> szerepel bennük.
@LvT: Addendum. Azért mégis ma is van nyomtatásban csehül <anjěl>, vö. VII. dal chasa-valtice.cz/wp-content/uploads/2010/09/pisnicky2.pdf , és <anjel>irodalmi szövegben is: www.lupomesky.cz/maj/
@Fejes László (nyest.hu):
.
> A vallási terminológia jóval hamarabb kialakult, mint a bibliafordítások megszülettek, hiszen a térítéshez is el kellett magyarázni a dolgokat
Hogy mennyire magyarázták el a térítéshez, az erősen kérdéses, lévén errefelé is a „cuius regio” elv mentén történt a keresztyénség felvétele. Másrészt családilag volt alkalmam a XX. sz.-ban összehasonlítani két paraszti vallásos vonalat, ahol maguk olvastak bibliát, és ahol nem. Ez utóbbi egyszerűen nélkülözte azt, amit vallásos terminológiaként definiálhatnánk. Harmadrészt éppen a Nyestről tudhatjuk, hogy hamarabb volt Magyarországon futball, mint magyar futballterminológia.
.
> A források szerint a korabeli latinban [nj] volt az ejtés, ami logikus is, hiszen így kerülhetett be a görögből.
Egyrészt ilyen forrással még nem találkoztam. Másrészt a pravoszláv nyelvekben, ahol közvetlenül a (bizánci) görögből vették át ezt a két szót, éppen hogy hiányzik, sosem adatolt a /j/-s alakváltozat. Sehol másutt nincs ebben a pozícióban /j/ történelmileg sem, csak ebben a három nyelvben. Ez tehát e három nyelv egyikében alakult ki: és ez csak a cseh lehetett.
.
> Azt nem értem, hogy jön ide a lengyel g, ha egyszer már a számba vehető forrásnyelvekben sem volt g a szóban.
A latin közvetítésű görög szavak, köztük a keresztyén terminológia, amíg ellátunk, addig az elől képzett mgh. előtt a lengyelben mindig /g/ van: <gehenna> stb. Nincs semmilyen adat arra, hogy a „forrásnyelvben” pl. ilyen helyeken /j/ lett volna.
.
> Valóban az én hibám, nem hangsúlyoztam, hogy amit írok, nem érvényes a 19. század elejéről vagy annál régebbről származó müzlisdobozokra.
A cseh is olyan, hogy a nyelvújítás eltávolította az irodalmi nyelvet a beszélt nyelvtől a környéken az egyik legnagyobb mértékben. És bizony, a XIX. sz.-i vagy még régebbi írt formákat folytató köznyelvi alakok ma is meg-megjelennek ma is írásban. És ez éppen lehet egy müzlisdoboz is.
.
> Szívesen vennék egy listát azokról a cseh szavakról
Nem adok ilyen listát, mert csak ezért nem fogom végignézni az engedélyezett összetevők, adalékanyagok listáját. Elég az, hogy posszibilisen nem 0 a valószínűség, és ezt szignifikánsan nem haladja meg a <nj> betűkapcsolatot tartalmazó, müzlisdobozra felkerülő horvát szavak frekvenciáját.
.
> Egyébként nézem annyira intelligensnek az olvasókat, hogy felismerjék, mik az idegen szavak a szövegben
Egyrészt, akkor minek kellett megírni a cikket, mert az annyira intelligens olvasó ezzel már tisztában lehetett. Ha meg nem, akkor ide másolom a korábbi bejegyzésből azt, amivel erre már egyszer válaszoltam: „Nem feltétlenül: ami az egyik nyelvben idegen szó, a másikban lehet nem az, vö. szerb <biblioteka> : horvát <knjižnica>. ha nem tudunk X nyelven, akkor egy maláj növény lisztjének nevéről nem biztosan ismerjük fel annak maláj és nem X nyelvi voltát, ha a mi nyelvünkben nem a maláj alakot használjuk.”
@LvT: A vallási terminológia jóval hamarabb kialakult, mint a bibliafordítások megszülettek, hiszen a térítéshez is el kellett magyarázni a dolgokat, tudunk imádságos könyvekről stb. Persze lehetnek olyan terminusok, melyek csak később alakultak ki.
A források szerint a korabeli latinban [nj] volt az ejtés, ami logikus is, hiszen így kerülhetett be a görögből. Ahol tehát [nj] van, ott a legegyszerűbb latin forrást feltételezni – ha nincsenek más hangtani (esetleg jelentéstani) kritériumok, amelyek mást sugallnak. Ha valaki ezt a lehetőséget kihagyja a lengyel etimológiai kutatások során, az magára vessen.
Azt nem értem, hogy jön ide a lengyel g, ha egyszer már a számba vehető forrásnyelvekben sem volt g a szóban. Azt pláne nem értem, miért kell feltételezni, hogy ha nem cseh jövevényszó a lengyelben, akkor csakis cseh jövevényszó lehet a lengyelben. Azt meg pláne nem, hogy éppen miért ne lehetne a forrása a szlovák. (A Nagy-Morva birodalom, az első szláv államalakulat, ahol jelentős mértékben megjelent a kereszténység, főként a mai Szlovákia területére esett.
„nem is írtam, hogy a mai csehet említettem volna” Valóban az én hibám, nem hangsúlyoztam, hogy amit írok, nem érvényes a 19. század elejéről vagy annál régebbről származó müzlisdobozokra. :)
„kis szerencsével a cseh is tud produkálni, hála a korszerű élelmiszeripar adalékanyagainak” Produkált vagy sem? Szívesen vennék egy listát azokról a cseh szavakról, melyek ilyen környezetben bukkantak fel, és lj vagy nj van bennük. Egyébként nézem annyira intelligensnek az olvasókat, hogy felismerjék, mik az idegen szavak a szövegben, és ne azok alapján próbálják meghatározni a nyelvet...
@LvT: Corrigendum
> nem „sakramentom”, hanem v, de még inkább „szentség”
nem „sakramentom”, hanem „szakramentum”, de még inkább „szentség”
@Fejes László (nyest.hu):
.
> A vallási terminológia azért jóval hamarabb kialakult, mint ahogy a bibliafordítások megjelentek, pláne a teljesek.
Én ebben nem lennék olyan biztos. Azt megelőzőleg ugyanis a latin volt a liturgiai nyelv: az anyanyelvi terminológia csak a bibliafordításokkal érett meg. De ugye magyar vonalon is felfigyelhetünk arra, hogy nem „sakramentom”, hanem v, de még inkább „szentség”.
.
> Érdekes lenne megnézni, hogy szerepelnek ez a szó ezekben a Bibliákban.
Bírák könyve 2,4 a králicei biblia szöveghű újrakiadásából: books.google.hu/books?id=jr5IAAAAcAAJ&pg=PA456&lpg=PA456&dq=%22Hospo
.
> Akárhogy is, mivel az [nj] egyértelműen a korabeli latin átvétele
Ez a tézis azért alátámasztásra szorulna.
.
> semmi nem igazolja, hogy a szlovákban cseh jövevényekről van szó
Már leírtam, sapienti sat. De még egyszer: a vonatkozó terminológia jelentős része a lengyelben és a szlovákban is cseh eredetű. A lengyel nem ódzkodik a /g/-től, és egy rövid időszakot leszámítva, a szlovák sem, így ezeknél a nyelveknél nem várható, hogy a [gʲ] > [j] hanghelyettesítést éppen ők találják fel, és az általános migrációs gyakorlattal ellentétben éppen ők adják át azt a csehnek. Ez a hanghelyettesítés a csehben lépett fel, és onnan került át a terminológia többi részletével a lengyelbe és a szlovákba.
.
> Hogy az anioł esetében mi az érv, azt nem értem.
Az érv itt a szláv filológia közvélekedése: a lengyel szó cseh eredetű és része a cseh eredetű keresztyén terminológiai rétegnek. Föl sem merül, hogy az lat. <angelus> szó régi [aɲjoɫ] és mai [aɲow] hantestének konszonantizmusát a latin és a lengyel közvetlen kapcsolatából magyarázzák, az ugyanis [anʲgʲoɫ]-t adott volna.
.
> Összességében mindez nem változtat azon, hogy a mai csehben nincs anjel és evanjelík.
Te mondod (ha kötözködünk, akkor persze megemlíthetem, hogy nem is írtam, hogy a mai csehet említettem volna). Ami a meritumhoz tartozik ennek kapcsán arról annyit vagyok mondandó, hogy ha nem is müzlisdobozon, de gyümölcsléén megnéztem a horvát feliratot. Nagyságrendileg annyi <nj>-t, amennyi abban volt, kis szerencsével a cseh is tud produkálni, hála a korszerű élelmiszeripar adalékanyagainak. Az <nj> stb. már fonotaktikai kérdés, így nem alkalmas a cikkben taglalt ökölszabályok közé.
@LvT: A vallási terminológia azért jóval hamarabb kialakult, mint ahogy a bibliafordítások megjelentek, pláne a teljesek.
Ezek a régi cseh bibliákból származó adatok valóban érdekesek, nem tudtam, hogy megkülönböztették a kettőt.
Azonban:
1. A mai csehben az angyal anděl, nem anjel. Érdekes lenne megnézni, hogy szerepelnek ez a szó ezekben a Bibliákban.
2. Akárhogy is, mivel az [nj] egyértelműen a korabeli latin átvétele, önmagában az, hogy a szlovákban és a csehben is ez van, semmi nem igazolja, hogy a szlovákban cseh jövevényekről van szó. Ehhez pontosan olyan érvek szükségesek, mint a lengyelnél a prorok esetében. (Hogy az anioł esetében mi az érv, azt nem értem. Persze ha egy szemantikai mezőben sok jövevényszó származik egy nyelvből, akkor feltételezhető, hogy a bizonytalan etimológiák is onnan származnak, de azért erre hivatkozni úgy, hogy és a lengyelben is...)
3. Összességében mindez nem változtat azon, hogy a mai csehben nincs anjel és evanjelík... :)
> A szlovákot ért cseh hatás csak a huszita kor utánról számítható. Azt azért nehezen hisszük, hogy a vallási terminológia csak ez után alakult ki a szlovákban, igaz?
.
Én azt tanultam, hogy a nyugati keresztyénségben a bibliafordítások mindenütt alapvetően hozzájárultak nemcsak a vallási terminológia kialakításához, de még a közös nyelvváltozat (a későbbi irodalmi nyelv) kialakításához is. A XIX. sz. közepéig nyílt kérdés volt, hogy lesz-e önálló szlovák irodalmi nyelv, vagy a morva sorsára jut, azaz a cseh annál is keletibb nyelvjáráscsoportjává válik.
Amúgy a szlovákban két egymás mellett élő vallási terminológiai rendszer élt: az evangelikus és a katolikus, éppen az eltérő bibliahasználat okán.
.
> Mint arról korábban írtunk, a cseh hejesírásban régebben a g jelölte a j-t. Előfordulhat tehát, hogy az evangelium és hasonló szavakban tévedésből [j]-t olvastak, és így terjedt el.
.
A könyvtáramban sok ilyen bibličtinában (bibliai cseh nyelven) írt nyomtatvány van, a legutóbbi dátuma 1917. De amellett, hogy a svabachi betűtípusban a <g> jelöli a /j/ hangot, van külön betű a /g/ hang jelölésére is, a mellékjeles <ğ>, pl. „Ale kdyǯ ʒ mrtwých wſtanu předegdu wás do Ğalilee”. Az evangélium értelmű szón azonban sosincs mellékjel: „Kdeǯkoli káʒano bude Evangelium toto po wſſem ſwětě”.
A két hang jelölése így eltért egymástól legalább annyira, mint az <c> /c/ és <č> /cs/-é, és ahogy az írás miatt ezek közt sincs tévesztés, úgy a /g/ és /j/ vonatkozásában sincs, „Ğalilea” nem lett /jalilea/-vá, és más sem. Szóval itt az íráskép tükrözi az ejtést, nem az ejtés az írásképet.
Szóval a szlovákban az <evanjelik> és az <anjel> cseh mintát tükröz.
.
Egyébként a cseh nemcsak a szlovák vallási (és egyéb) terminológiára hatott, de a lengyelre is. Szemléletes példa a <prorok> ’próféta’ szó, amely egyaránt megvan a csehben, szlovákban, lengyelben, de az alakja egyértelműen csehes, mivel a <pro-> ’túl-, át-’ ebben a nyelvben igekötő, vö. cseh <pro|rok> ← <pro|řek|nouti> ’kijelent, kimond’ : szlovák <pre|riek|nuť> ’szól, megszólal’ : lengyel <*prze|rzek|ać> (vö. <prze|mów|ić> ’beszél’, ill. <o|rzek|ać> ’kimond, ítéletet mond’). Nem meglepő, hogy a lengyelben <aniół> ma az ’angyal’, amely a XIV. sz.-tól adatolható, először <ańjoł> formában. Erről Wiesław Boryś is azt írja a lengyel etimológiai szótárában, hogy „[z]apożyczone wraz z innymi terminami chrześcijanskimi ze st[aro]cz[eskiego] <anjel>” ’más keresztyén szakszavakkal együtt az ócseh <anjel>-ből kölcsönözve’.
@scasc: Minden régió határának meghúzása önkényes. A cikk pontosan leírja, hogy ebben az esetben mit tekint régiónak. A németet egyébként azért a magyarok többsége – legalábbis akinek kedve van nyelvazonosítósdit játszani – könnyen felismeri.
@scasc: Nyelvi adatok híján ez nehezen eldönthető, ettől függetlenül ez a bonyolultabb magyarázat. Ráadásul ha a csehben ennyire automatikus lett volna a csere, akkor ma nem anděl lenne, hanem angel...
@Fejes László (nyest.hu): Simán lehet, hogy az íráskép alapján a latinból átvett angel-t az egyéb íráshagyomány miatt (ami németföldi eredetű) kezdettől /j/-vel olvasták. Amikor a cseh helyesírás a /j/-ben lecserélte a grafémát, ezeknél a nemzetközi műveltségi szavaknál feltehetőleg "etimologikus" elvet alkalmazott, miként megtartotta a <g>-t.
"A szlovák felismeréséhez segítség lehet az ä is, mely a régióban a szlovákon kívül csak az észtben fordul elő."
Szerintem a "mi" régiónkba beletartozik a német is...
@LvT: A szlovákot ért cseh hatás csak a huszita kor utánról számítható. Azt azért nehezen hisszük, hogy a vallási terminológia csak ez után alakult ki a szlovákban, igaz?
Mint arról korábban írtunk, a cseh hejesírásban régebben a g jelölte a j-t. Előfordulhat tehát, hogy az evangelium és hasonló szavakban tévedésből [j]-t olvastak, és így terjedt el. Az anjel esetében azonban ez a magyarázat nem állhat – hacsak nem volt a csehben korábban angel.
Máchek cseh etimológiai szótára szerint a szó középkori latin kiejtése [anjel] volt, majd a zár elnyúlásával keletkezett a [gy]. (Ez probléma lehet a magyarban is, de a TESz. nem tér rá ki.) Ezek szerint viszont a szlovák anjel az archaikusabb alak.
Az evangel- típusúakra Máchek nem tér ki. A TESz. külön erre a kérdésre itt sem, de az adatokból kiderül, hogy korábban a magyarban az evan[gy]él- alakok voltak a gyakoribbak (de ugyebár amit simán g-vel írtak, az is rejtheti ezt az ejtésmódot), ami arra utal, hogy a magyarban is olyan lehetett a fejlődés, mint a csehben – tehát megint a szlovák az archaikus.
@Fejes László (nyest.hu): > Nem látom sem nyelvi, sem kulturális okát annak, hogy azt feltételezzük, hogy ezek a csehből kerültek volna a szlovákba
Én szlovák vagyok, aki a templomban tradícionálisan cseh orációt hallgat, így tudom, hogy mi jött honnan, mert ezek még élő kapcsolatok.
A csehben tradícionálisan nincs <g>, még kevésbé, mint a szlovákban. Ugyanakkor a cseh az írodalmi és a köznyelv meglehetősen távol áll egymástól, és az egy dolog, hogy most hogy szótárazzák az <evangelik>-ot, és más dolog, hogy adott környezetben hogyan írják le.
.
> az idegen szavak bármikor kivételt jelenthetnek Jó esetben azonban ezeket felismerjük.
Nem feltétlenül: ami az egyik nyelvben idegen szó, a másikban lehet nem az, vö. szerb <biblioteka> : horvát <knjižnica>. ha nem tudunk X nyelven, akkor egy maláj növény lisztjének nevéről nem biztosan ismerjük fel annak maláj és nem X nyelvi voltát, ha a mi nyelvünkben nem a maláj alakot használjuk.
@LvT: Az anjel csehül anděl, az evanjelík evangelík. Nem látom sem nyelvi, sem kulturális okát annak, hogy azt feltételezzük, hogy ezek a csehből kerültek volna a szlovákba – hacsak nem írástörténeti oka van, de ebben az esetben sem érezném annyira meggyőzőnek a magyarázatot.
Természetesen az idegen szavak bármikor kivételt jelenthetnek. Jó esetben azonban ezeket felismerjük.