
J. K. Rowling, Óz és az alkotmányos levelek esete a számítógépes nyelvészettel
Harry Potter anyukája, J. K. Rowling titokban krimiírói babérokra pályázott. A számítógépes nyelvész viszont lebuktatta az álnéven publikáló sztárírót. A Kereső Világ cikkéből és a titokzatos Óz segítségével azt is megtudhatjuk, hogyan!
A brit The Sunday Times igazságügyi nyelvészeket kért fel, hogy megállapítsák, kit takar a Robert Galbraith álnév. Ahogyan arról többen is beszámoltak, a Rowlingot képviselő ügyvédi iroda egyik munkatársa kotyogta el barátnőjének, hogy a szerző álnéven jelentette meg legújabb regényét. A hölgy a Twitteren gyorsan meg is osztotta információit a világgal, majd rájött, hogy ez nem volt jó ötlet, és törölte a bejegyzését. A szemfüles újságírók azonban nem adták fel. Számítógépes nyelvészekhez fordultak, akik arra a következtetésre jutottak, Galbraith és Rowling nyelve nagyon közel áll egymáshoz. Posztunkban körüljárjuk a szerzőség megállapításának módszereit, és statisztikai képletek helyett grafikonokkal szemléltetjük az eljárás menetét.

Hogyan bukott le Rowling?
A Sunday Times Patrick Juola és Peter Millican segítségét kérte a szerzőség megállapításában. A két szakértő egymástól függetlenül dolgozott, de nagyon hasonló módszereket használtak. Sajnos még nem sikerült Juola vizsgálatáról részletes leírást találnunk, de Millican a Language Log olvasóival megosztotta eljárását. Röviden összefoglalva: Millican öt különböző szerzőtől származó kötet szövegét kapta meg elektronikus formában. A szerzők közül kettőre (Val McDermid és J. K. Rowling) gyanakodtak, hogy esetleg a The Cukoo's Calling szerzője lehet, a többi szerző vizsgálata pedig azt a célt szolgálta, hogy a kutatók lássák, mennyire tér el a vizsgált mű más szerzők szövegeitől.
A JGAAP program segítségével négy különböző vizsgálatot futtatott le Millican: szóhosszúsági eloszlás, a száz leggyakrabban használt szó gyakorisági eltérései, szó bi-gramok elemzése és 4-gram karakterláncok elemzése. Habár McDermid is jó esélyesnek tűnt, egyedül Rowling eredményei voltak következetesen jobbak minden vizsgálatban.

Hogyan zajlik egy ilyen vizsgálat?
Nem biztos, hogy szép dolog egy még élő alkotót lebuktatni... de mindenképpen izgalmas. Azt, hogy hogyan is zajlik egy ilyen vizsgálat, két régebbi történet segítségével, két klasszikus mű és két klasszikus szerzőségi vita apropóján mutatjuk be. Az is kiderül, hogy mi a közös az Óz-könyvekben és az amerikai alkotmányban.
A Federalist Papers néven emlegetett művet Alexander Hamilton, James Madison és John Jay írta és jelentette meg Publius álnéven különböző folyóiratokban 1787 és 1788 között. A 85 esszé célja az volt, hogy az alkotmányt elfogadása előtt népszerűsítse és értelmezze. A célját messzemenőkig elérte, a Federalist Papers a mai napig hivatkozási alap az Egyesült Államok alkotmányának értelmezésében és a legfelsőbb bíróság ítéleteiben is gyakran hivatkoznak soraira.
Nem sokkal Hamilton halála után egy lista került napvilágra, melyen Hamilton magának tulajdonította a szövegek kétharmadát, ráadásul sok olyan írást is a sajátjaként nevezett meg, amelyek szerzőjeként a korabeli közvélemény inkább Madisont ismerte el. Az esszék szerzőségének megállapítása külön tudományággá fejlődött az idők során. Douglass Adair, a Yale történész doktorandusza disszertációjában arra jutott, hogy az esszék az alábbiak szerint oszlanak meg a szerzők között:
- Alexander Hamilton: 51 db;
- James Madison: 26 db;
- John Jay: 5 db;
- Madison és Hamilton közösen: 3 db.
Adair alapvetően stílusérzékére és történészi vénájára hagyatkozva állapította meg az egyes írások szerzőinek kilétét – 1944-ben még nem is nagyon tudott volna számítógépeket bevetni erre a vizsgálatra. De huszonhárom évvel disszertációjának megírása után lelkes statisztikusok vették elő újból a nagy hatású művet.

1967-ben Frederick Mosteller és David L. Wallace számítógépes vizsgálataikkal megerősítették Adair eredményeit, amit a bayesiánus számítógépes nyelvészet előfutárának tartott Applied Bayesian and Classical Inference, The Case of The Federalist Papers című könyvükben foglaltak össze. Lassan ötven év telt el a mű megjelenése óta, de minden új szerzőség megállapítására írt algoritmust illik kipróbálni a Federalist Papers korpuszán.

Az Óz sorozat kötetei több szerzőtől származnak. A The Royal Book of Oz L. Frank Baum neve alatt jelent meg, de az általánosan elfogadott nézet szerint Ruth Plumly Thomson írta. Ingo Feinerer nyomán az alábbi kötetekkel vetettük össze a vitatott művet (a munkák a Project Gutenberg-ről szabadon letölthetőek):
- The Wonderful Wizard of Oz (Baum);
- The Marvelous Land of Oz (Baum);
- Ozma of Oz (Baum);
- Ozoplaning with the Wizard of Oz (Thomson).
Vizsgálódásaink során a kötetek szövegeit ún. szó-dokumentum mátrixba (Term-Document Matrix) tettük. A mátrix tulajdonképpen egy táblázat: oszlopai egy-egy dokumentumot (jelen esetben könyvet) reprezentálnak, sorai pedig az összes dokumentumban előforduló szavakat, valahogy úgy mint az alábbi ábrán:
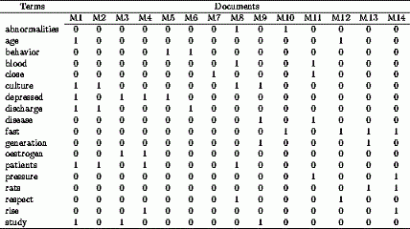
Az ilyen táblázatokban gyakran találkozhatunk nulla és egy értékekkel, hiszen egyes szavak csak egy-egy dokumentumban fordulnak elő. Hogy ne kelljen a számítógépnek túl sok erőforrást használnia, a vizsgálatok jelentős részénél elvetettük a ritka elemeket, ezzel jelentősen csökkentettük a mátrixok méretét. A táblázatok összehasonlítására az úgynevezett főkomponens-analízist (principal component analysis, azaz PCA-t) használtuk, és két összetevőt kerestünk minden esetben. A PCA neve alapján komoly és száraz dolog, de igazán kényelmes módszer arra, hogy a gép számolja ki helyettünk, mennyire hasonlít egymáshoz két mátrix. A választott elemzési módszer lehetővé tette azt, hogy hátradőljünk, és csak azzal foglalkozzunk, hogy milyen műveleteket végezzünk a szövegen.
Millicanhez hasonlóan feldaraboltuk a szövegeket, mi általában 100 soronként. (Nem a húrt szeretnénk tovább feszíteni, csak a nagyon vájtfülűek kedvéért jegyezzük meg, hogy a vizsgálatok során az R statisztikai programozási nyelv tm és kernlab csomagjait használtuk.) A grafikonokon az egyes művek „darabjait″ az alábbi színeknek megfelelő körök jelölik:
- fekete - The Wonderful Wizard of Oz (Baum)
- piros - The Marvelous Land of Oz (Baum)
- kék - Ozma of Oz (Baum)
- zöld - Ozoplaning with the Wizard of Oz (Thomson)
- sárga - The Royal Book of Oz
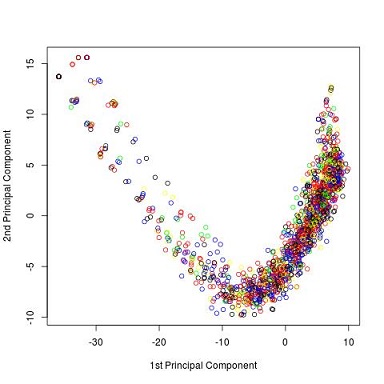
Először a szövegeket mindenféle feldolgozás nélkül tettük mátrixba és kiszűrtük a legritkább 20%-át az előforduló szavaknak. Látható, hogy ez nem vezetett sok eredményre, a különböző színű pontok nagyon közel vannak egymáshoz, nincs semmilyen jól kivehető mintázat szerveződésükben. A PCA algoritmus az ún. bináris-relációk, azaz a táblázat celláinak értékei közötti különbség alapján dolgozott.
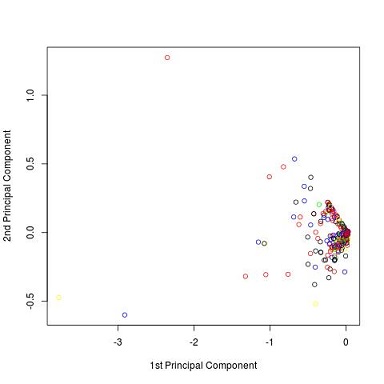
A következő lépésben a PCA alapbeállításától eltértünk, s a gyakorisági értékek csökkenő sorrendjét vettük kiindulási pontnak. A fekete, piros és kék pontok (Baum szövegei) egyértelműen közel kerültek egymáshoz, de a zöld és a sárga (Thomson) színnel jelzett adatok nem tartanak egyértelműen egyik csoporthoz sem.
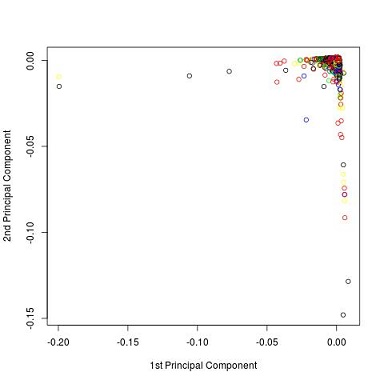
Ezután a szövegeket normalizáltuk, azaz minden karaktert kisbetűsre alakítottunk, kiszűrtünk minden nem-karaktert (számok, írásjelek) kiszűrtük a stopszavakat és szótövezést végeztünk. Látható, hogy sok pont átfedésbe került egymással az ábrán, de a zöld-sárga és a sárga-piros adatpontok közelsége kezd kirajzolódni.
Megnéztük, hogy a funkciószavak (tulajdonképpen a stopszavak listájára tett és kiszűrt névelők, névmások stb.) és írásjelek mátrixai milyen képet mutatnak. Itt is a sárga-zöld ill. sárga-piros közelséget találjuk.
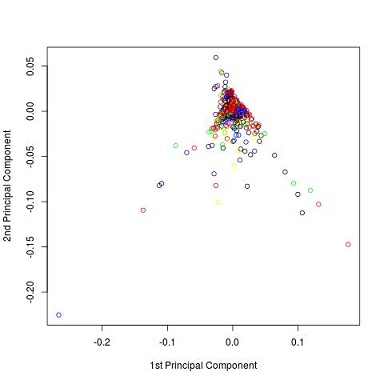
Mi van, ha akad egy kellően erős gépünk, és minden szűrés nélkül a teljes szöveget tudjuk vizsgálni a PCA technikával? Az alábbi ábrán látható, milyen eredményt kaptunk, ha a szöveget ötszáz soronként daraboltuk fel.
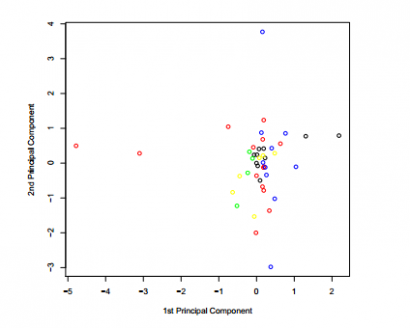
Tovább finomodott a helyzet, amikor száz soronként daraboltuk fel a szöveget. Itt már egyértelműen látszik a sárga és a zöld adatpontok közelsége, azaz hogy Thomson a The Royal Book of Oz szerzője.
Joggal merülhet fel az olvasóban, hogy miért végeztünk el sok vizsgálatot, melyek grafikonjain alig látszott valami eredmény. A válasz az, hogy hiába csupán pár megabájtnyi az öt kötet, a dokumentummátrixok és a rajtuk végzett PCA-műveletek erőforrás-igényesek. Egy jobb, 8GB memóriával rendelkező laptopon is könnyen kifuthatunk a rendelkezésre álló memóriából egy ilyen elemzés során (ez a szerzővel meg is esett, miközben a cikk írására készült). A négy előzetes vizsgálat közül három statisztikailag szignifikánsan mutatta ki (még akkor is ha grafikonon nem is tudta jelezni), hogy Thomson a kérdéses mű szerzője. Mind a négy vizsgálat elvégezhető gyorsan egy átlagos laptopon, együttes eredményeik pedig még erősebbek is, mint a nyers erővel végzett vizsgálat.
@ocs: ott a pont, köszi hogy jelezted
Bocs, csak a jegyzőkönyv kedvéért, de lehet, hogy ez:
"Millican a Language Log olvasóival megosztotta eljárását"
pont mégis Juola:
"[Guest post by Patrick Juola]"