
Egy elfeledett nyelv megfejtése - avagy mi köze Hurászánu főpap fejszéjének a számítógéphez
A közelmúltban sikerült számítógéppel, automatizáltan megfejteni az ugariti írást. Habár ezeket az ékírásos táblákon fönnmaradt szövegeket kutatók már a múlt században olvashatóvá tették, ehhez akkor több nyelvész erőfeszítésére volt szükség. Vajon az új eredmények segíteni fognak abban, hogy eddig visszafejtetlen írásos emlékeket is értelmezni tudjunk?
A közelmúltban járta be a világsajtót az a hír, miszerint sikerült számítógéppel, teljesen automatizáltan megfejteni az ugariti írást. Habár ezeket az ékírásos táblákon fönnmaradt szövegeket kutatók már a múlt században olvashatóvá tették, ehhez akkor több nyelvész erőfeszítésére volt szükség. Vajon az új eredmények segíteni fognak abban, hogy eddig visszafejtetlen írásos emlékeket is értelmezni tudjunk?

(Forrás: Wikimedia Commons)
Ugariti, az ékírásos héber?
Ugarit ókori városállam a Földközi-tenger partján, a mai Szíria nyugati részén helyezkedett el. Fénykorát i. e. 1450 és 1200 között élte, de már az i. e. 5. évezredben lakott volt. Miután a tengeri népek támadása következtében elnéptelenedett, pontos helye évszázadokra feledésbe merült. Csak 1928-ban bukkant rá újra egy földműves Rász Samra arab falu mellett, amikor szántás közben elmozdított egy nagy kőlapot és alatta rejtélyes sírkamrák kerültek napvilágra. A lelőhely feltárása szinte azonnal megkezdődött, és a régészek többek között könyvtárakat, bennük pedig számos ékírásos agyagtáblát találtak. Néhány közülük ismert nyelveken íródott, sumérul, akkádul; de a többség egy ez idáig ismeretlen nyelven, amit a kutatók ugaritinak neveztek el. Maguk az ékírásos jelek is különböztek a megszokottaktól – az ugariti karakterkészletet azóta sem sikerült a mezopotámiai ékírásokra visszavezetni, a hasonlóságok valószínűleg csak a használt eszközök miatt adódtak.
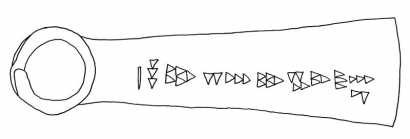
Charles Virolleaud francia asszirológus próbálkozott először a megfejtéssel. Megállapította, hogy a táblákon 30 jel szerepel különböző kombinációkban, tehát valószínűleg ábécéről van szó és nem szótagírásról. Mivel a szavak rövidek, a magánhangzókat feltételezhetően nem jelölték. Virolleaud először ciprusi eredetűnek gondolta a feliratokat. Felfedezte azt is, hogy több fejszén hasonló négy jelből álló sorozat található, és arra gondolt, ez a „fejsze” szó lehet, de még nem talált neki más nyelvű megfelelőt.

(Forrás: Wikimedia Commons)
Miután Virolleaud megjelentette eredményeit és közzétette a feliratok másolatát, a tényleges dekódolás felé az első lépéseket Hans Bauer német és Édouard Dhorme francia kutatók tették meg 1930-ban, egymástól függetlenül. Mindketten abból az elképzelésből indultak ki, hogy az ugariti sémi nyelv, többek között a héber rokona. A sémi nyelvekre jellemző prefixumok és toldalékok ismeretében az azokhoz hasonló eloszlást mutató ismeretlen jeleket megfejtették, és innen tovább nagyon gyorsan az egész ábécét értelmezni tudták. Bauer, miután hozzájutott a feliratokhoz, 5 nap alatt 17 betűt azonosított helyesen, annak ellenére, hogy a „fejsze” szóra a héber grzn-t (ejtsd gárzén = fejsze) használta a később helyesnek bizonyult hrṣn helyett. 1932-re teljesen készen állt az ugariti ábécé és olvashatóvá váltak az ugariti szövegek. Kiderült, hogy ez a nyelv valóban a héber közeli rokona, de nem egyezik meg vele – tehát nem arról van szó, hogy héberül írtak másfajta ábécével.
Automatikus visszafordítás
Ugrás a mába: Benjamin Snyder, Regina Barzilay és Kevin Knight amerikai kutatók tették közzé idén azt az eljárást, amelynek segítségével a nyelvészek által végzett visszafejtés teljesen automatizálható. A módszer meglehetősen hatékony: a 30 ugariti betűből 29-et sikeresen hozzárendel a héber megfelelőjéhez (mivel a héber ábécében csak 22 betű van, ezért van, amelyikhez többet), és morfológiai elemzést végezve a héber megfelelővel rendelkező szavak 60 százalékát és alkotóelemeik 71 százalékát is sikeresen azonosítja a héber változattal. Ez annál inkább figyelemreméltó, hogy az ugariti nyelvtanában is különbözik a hébertől, például nem használ határozott névelőt. (A fennmaradt és a szerzők által felhasznált ugariti szövegekben a szavak egyharmadának van héber megfelelője, a többi nagy része tulajdonnév vagy megtalálható más sémi nyelvekben.)
Ahhoz, hogy az algoritmus működjön, nem kell semmiféle szótár (Rosette-i kő) vagy párhuzamos ábécé, néhány más információra azonban szükség van. Tudni kell például, milyen nyelv rokona az ismeretlen nyelvnek – emlékezzünk, az ugariti esetében ez először nem volt egyértelmű! – és szükség van nagy mennyiségű szövegre az ismert rokon nyelven. (Knight és csoportja a héber Bibliát használta erre a célra.) Csak ábécés írásokat lehet vizsgálni, emellett tudni kell, hol vannak a szóhatárok, és el kell tudni különíteni a betűket. Az ugariti ideális ebből a szempontból, mert nem folyóírással íródott, és külön karaktert használ a szóközök megjelenítésére – de például a mai napig megfejtetlen Voynich-kézirat esetében még a betűk mibenlétéről sincsen teljes egyetértés. Emellett szükség van még arra is, hogy tudjuk, az ismert rokon nyelv milyen toldalékokat használ és milyen gyakoriságokkal, de ezek az adatok általában rendelkezésre állnak.
Az eljárás bármilyen nyelvre használható, ha az kielégíti a fentebbi feltételeket, de bele lehet építeni az aktuálisan dekódolandó szöveganyagról meglévő tudást is a különböző paraméterek okos megválasztásával. Jelen esetben, mivel például az átlagos ugariti szó két betűvel hosszabb az átlagos héber szónál, feltételezhető, hogy a héber szavakból nem kell betűket törölni, hogy eljussunk az ugariti megfelelőkhöz.

(Forrás: Wikimedia Commons)
Tulajdonképpen ugyanaz történik, mint a kézi dekódolásnál: a program kikeresi a toldalékoknak tekinthető ismétlődő szakaszokat a szavak végén és elején (a sémi nyelvekben gyakoriak a prefixumok), és az ismert nyelvben meglévő toldalékgyakoriságok alapján megpróbálja megállapítani, melyek lehetnek az egymásnak megfelelő toldalékok az ismert és az ismeretlen nyelvben. Ha a megfelelő betűk megvannak, akkor a szótövekbe is be lehet helyettesíteni őket és egyszerűen elolvasni a szöveget. Eközben azt is tekintetbe kell venni, hogy a két nyelv hangjai (és ebből következően az írás betűi) között nincsen tökéletes egy az egyhez jellegű megfelelés, habár szerencsére egy betűhöz általában maximum három betű rendelhető a másik írásban. Ügyelni kell arra is, hogy a különböző szófajokhoz különböző toldalékgyakoriságok tartoznak. Mindezekre már képes a cikkben leírt eljárás, viszont még nem tud a szövegkörnyezet alapján következtetni.
Jó ez nekünk valamire?
Az eredeti publikáció kicsit csúsztatva arról beszél, hogy „gyakran évtizedeken át tartó kutatói erőfeszítésre volt szükség” hasonló eredmények eléréséhez számítógép nélkül, de ahogy feljebb láthattuk, ez pont az ugaritira nem áll. A jelenleg megfejtetlen írásos leletek esetében pedig általában nem állnak fenn azok a tényezők, amik az új eljárás használatát lehetővé tennék: nem tudjuk, milyen nyelvcsaládhoz tartoztak a nyelvek, amiken írtak, nem maradt fenn a statisztikai elemzéshez elegendő mennyiségű anyag, és így tovább.
(Forrás: Wikimedia Commons)
Az sem igaz, hogy az ugariti szövegeket a fejszék feliratának ismerete, tehát egy „szerencsés véletlen” nélkül nem tudták volna a nyelvészek értelmezni. Mára már sokan úgy gondolják, a négybetűs szó tulajdonnév és a fejsze birtokosának, a gazdag Hurászánu főpapnak a neve! Az efféle kontextusbeli finomságokkal pedig az új eljárás nem tud mit kezdeni.
Arról sem szabad elfeledkezni, hogy az írás nem azonos magával a nyelvvel – ha az ábécé ismeretében tudjuk, hogyan kell felolvasni egy szöveget, még nem biztos, hogy a jelentésével is tisztában vagyunk (habár itt a héber megfelelőkből lehet valamilyen szinten következtetni, de ne feledjük, számos ugariti szónak nincsen héber analógja). Viszont maga a módszer vagy egyes elemei hasznosak lehetnek más fordítással kapcsolatos alkalmazásokban.
Ha a mássalhangzókat (a változó hangok figyelembe vételével) meg lehet állapítani, s a gyökök "elvont" közös értelme már megvan (mondjuk jobb volna nemcsak két hanem 4-5 gyöknyelv kivonatolása után - a gyöknyelvészet módszerével),
akkor némi próbálkozással bármilyen abc írást és szótagírást egyaránt meg lehet(ne) fejteni.
Még a változó hangok "belépését" is lehet valószínűsíteni, vagy kizárni a megjelenési góctól kiinduló területi elterjedésük feltérképezésével.
Persze addíg, amíg nem kell az evolúciós gyöknyelvészet, addíg
a cikkben olvasható nehézségek fognak megmaradni.