
Adatok, filozófia, nyelvészet
A web2.0 megjelenésével ma már minden alkalmazás „data-driven”, azaz adatvezérelt. A cikk azt mutatja be, hogyan vezetett az adatok kezelésének gyakorlati problémája egy új tudományág megszületéséhez. A mélyen elméleti megközelítést szemléletes példák teszik érthetővé.
Az adatvezéreltség nemcsak azt jelenti, hogy valahol a mélyben van egy adatbázis, amin az alkalmazás bizonyos művelteket végez, és a felhasználó örül (mert rendelt egy neki megfelelő repjegyet, könyvet vagy bármilyen terméket), hanem hogy maga a felhasználó is aktívan adatokat generál, amit a rendszer rögzít, és valamilyen módon felhasznál (különböző ajánló rendszerek, kapcsolati hálók feltérképezése stb). Az adat szóra mindenki számokra gondol, de a weben szörfölő felhasználó maga nem csak számokat generál (látogatottsági gyakoriság, szerver logok stb), hanem egyre nagyobb mennyiségben szöveges (és egyre nagyobb arányban multimédiás) tartalmakat (űrlapok kitöltése, egy profil megírása, különböző szöveges adatfolyamok stb).

(Forrás: Wikimedia commons / U. S. Navy)
A cikk eredetileg a Számítógépes nyelvészet című blogon jelent meg.
Ezen adatok betekintést engednek a felhasználók viselkedésébe, és a szolgáltató cégek egyre nagyobb számban alkalmaznak különböző technikákat ezek elemzésére, ami amellett, hogy egyre jobb szolgáltatásokat eredményezhet, rengeteg jogi/etikai problémát is felvet (melyekkel mi most nem foglalkozunk). Ez az igény egy új, alkalmazott tudományág az adatok tudománya megszületéséhez vezetett, ami az alkalmazott statisztikát, a számítástudományt és az interakciódizájnt ötvözi egybe. Természetes hát, hogy nyelvi adatok elemzéséhez felhasználják a számítógépes nyelvészet eredményeit, habár ez gyakran elsikkad. Ebben az írásban megpróbálom összefoglalni, milyen szerepe lehet kedvenc tudományterületünknek ebben az új tudományban, és mit használhatunk fel belőle. Ezért hát az idézet: a nyelvi adatok megmutatják, hogyan használjuk a nyelvet, az adatok tudománya pedig segíthet meglátni az összefüggéseket. Az adatok tudományának pedig segíthetünk „köztes tagokat” biztosítani az adatok jobb megértéséhez.
Wittgensteiniánus számítógépes nyelvészet?
“Értetlenségünk egyik fő forrása, hogy szavaink használatát nem látjuk át. – Grammatikánkból hiányzik az átláthatóság. – Az áttekinthető ábrázolás közvetítésével jön létre a megértés, amely éppen azt jelenti, hogy »látjuk az összefüggéseket«. Ezért olyan fontos, köztes tagokat találjunk, illetve kitaláljunk. Az áttekinthető ábrázolás fogalma alapvető jelentőségű számunkra. Ábrázolási formákat jelöl, azt a módot, ahogyan a dolgokat látjuk. (»Világnézet« ez vajon?)” (§.122.) [Wittgenstein: Filozófiai vizsgálódások, Atlantisz, 1998]
Yorick Wilks What would a Wittgensteinian computational linguistics like be? (Milyen lenne egy wittgensteiniánus számítógépes nyelvészet?) cikkében amellett érvel, hogy a szemantikus web adhat választ arra, miképp konstruálódik a jelentés a különböző használati módokban. A különböző ontológiák (jelentésleírások) egyszerre „fentről” (a magasabb rendű fogalmak feltérképezésével) és „lentről” (az alapfogalmak meghatározásával) építik ki az alapvető szemantikai értelmezéseket, amik – ha minden jól megy – a különböző területek ontológiáinak összekapcsolásával majd betekintést nyújtanak abba, hogy a nyelv egészében hogyan jön létre a jelentés. A klasszikus mesterséges intelligencia a logika minden eszközét bevetve próbálta meg leírni az intelligens viselkedést, de a kilencvenes évekre kifulladt.
Az „adatok forradalma” a statisztikai módszerek diadalát hozta a számítógépes nyelvészetben, és később a nyelvészetben is. Ez pedig egyrészt az alapoktól való eltávolodást (Chomsky és tanára, Carnap szabályalapú megközelítése) és a behaviorizmus különböző formáinak reneszánszát vonta maga után. Quine és Davidson radikális interpretációja megtámogatható a statisztikai fordítás paradigmájával, hiszen nem egy az egyben adunk megfeleltetést, hanem „a legjobb tippet” keressük meg, a megmaradó bizonytalanság pedig értelmezhető Quine módjára.
A híres gavagai-példa szerint: ha elvetődünk egy eddig elszigetelt törzshöz, és szeretnénk leírni nyelvüket, megfigyeléseket végzünk, nyelvi adatokat gyűjtünk, és megpróbáljuk a nyelv szabályait a beszélők viselkedéséből, reakcióiból „lepárolni”. Ha elkísérjük a törzs egyik tagját útján és meglát egy nyulat, majd felkiált, hogy „gavagai”, lejegyezzük, és megpróbáljuk értelmezni ezt a viselkedés. De hogyan fordítsuk le ezt magyarra?

(Forrás: Wikimedia commons / Duncan Grey)
„Nyúl”, de lehet hogy „ott egy nyúl” vagy „az ott egy nyúl”, de akár lehet „az lesz a mai vacsora” is. Nyilván praktikus eszközökkel le tudjuk szűkíteni a lehetséges interpretációkat (pl. ha este, amikor a tányérunkra kerül egy darab hús, és ismét azt halljuk hogy „gavagai”, akkor szűkül a kör, de még mindig lehet egyszerre vacsora és nyúl is a lehetséges fordítás). Quine szerint mindez azért van, mert az értelmezésekhez az egész nyelvet „egyszerre” kellene tudnunk előre, mivel nem szimplán mondatokat tanulunk, hanem azok összefüggéseit és a hozzájuk kapcsolt empirikus tapasztalatot is, így a nyelv mondatai absztrakciók csupán, jelentésüket a nyelv egészétől kapják, nem pedig az egyes mondatok adják össze a nyelv egészét.
Wilks értelmezésében Wittgenstein nem veti el a klasszikus megközelítést, de kétli, hogy lehet átfogóbb képünk róla (gondoljunk itt a korai Wittgenstein Tractatusára). Ahogy a fenti idézet is mutatja, ha meg akarjuk ragadni a „szavaink használatát”, és át akarjuk látni a grammatikát, eszközöket kell keresnünk és készítenünk. A logika egy eszköz, ami nagyon durván egy általános szintet ír le, míg a használatot az adatok halmaza adja meg, amit a statisztika segítségével elemezhetünk. Ha ezt elfogadjuk, akkor mindegy milyen elméleti talajon állunk (szabály-alapú vagy statisztikai megközelítés), el kell fogadjuk, hogy a nyelv mint egész megértése lehetetlen (ezt súgják nekünk a meta-logikai tételek is), ezért arra kényszerülünk, hogy különböző eszközökkel „barkácsoljunk”. Az adatok tudománya segíthet nekünk megérteni a nyelv használatát, a leíró statisztikák emészthetővé teszik az adatokat, és bemutatják a különböző használati formákat. Az „áttekinthető ábrázolás” , az eredmények prezentálása pedig segít látni az összefüggéseket. Igaz nem váltjuk meg velük a világot, de segítenek nekünk jobban eligazodni a világban.
Az adatok tudománya – miért nem szimplán statisztika?
Az adattudomány (data science) mint fogalom új, és csak 2010 június 2-án vált bevett fogalommá igazán, amikor Mike Loukides „What is Data Science?” O'Reilly Radar Reportja megjelent. Az írás rendkívül népszerű lett, és habár maga a kifejezés már előtte is megjelent és használatban volt egy szűk körben, sokat lendített a az adatok tudományának ismertségén. A cikk elolvasása mindenképpen ajánlott: nem túl hosszú és könnyen olvasható (amolyan ismeretterjesztő cikk), itt inkább csak azokat a részeit emeljük ki, amelyek rávilágítanak arra, hogy miben más ez, mint a statisztika.
- Az elektronikus formában gyűjtött és tárolt adatok értelmezése (parsing) is az adatok tudományának része.
- Igazán nagy mennyiségű adat feldolgozásával foglalkozik, ennek feldolgozása maga mindig a probléma része. Így a különböző skálázható adattárolási és feldolgozási módszerek (pl. MapReduce, felhőszámítás, stb) az praktizáló adat tudós eszköztárának részei.
- Az adatok bemutatása nem csupán statikus, egyszerű táblákkal és grafikonokkal történik. Az igazán nagy adatok vizualizálásához kifinomult eszközök kellenek, melyek lehetővé teszik akár az interakciót is. Így az adattudós valamennyire ért az interakciódizájnhoz és az információ vizualizációjához (információgrafikához) is.
Nyilván ennél jóval többet jelent az adatok tudománya. Edd Dumbill „Data Week: Becoming a Data Scientist” írásában így foglalja össze Alex Kamil kitűnő válaszát (ami eredetileg a Quora-n olvasható itt) arra hogyan lehet valaki adattudós: Kamil kezdőknek szánt ajánlásai a magukat adattudósként meghatározók közös vonásaira emlékeztetnek:
- Kezdjen el statisztikát tanulni az R nyelvben történő programozás során, mivel mindegy, hogy mekkora adathalmazzal dolgozik, a legtöbb adatelemző platform és prototípus az R nyelvet használja. Néhány a (munkafolyamat egy későbbi pontján) lefordítja ezeket map-reduce feladatokra – pl. hogy egy Hadoop instancián futtassák. Az R nyelv egy praktikus megközelítés a fejlesztők számára, hogy gyakorlatban tanulhassanak statisztikát.
- Lineáris algebra: a legtöbb adattudós biztos lineárisalgebra-tudással rendelkezik, és ez nagyon fontos, mivel a mátrix számítás húzódik meg a legtöbb adatbányászati alkalmazás, így a híres PageRank algoritmus mögött is.
- Gépi tanulás: Innovatív adatalapú termékek és szolgáltatások fejlesztéséhez alapvető követelmény, hogy a számítógépek viselkedését megváltoztathassuk a bemeneti adatok hatására. A legtöbb fejlesztő ezt ad-hoc módon sajátítja el, de Kamil Bradford Cros átfogó listáját ajánlja. [Cros az adattudománnyal foglalkozók körében népszerű Measuring Measures blog szerzője, az egyik első sikeres adat startup elindítója]
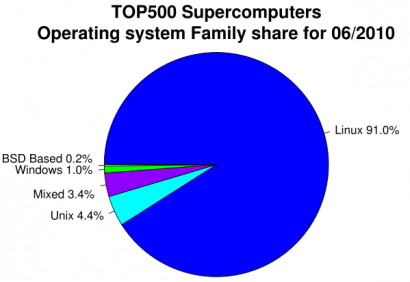 Az operációs rendszerek megoszlása a szuperszámítógépeken. Egyszerű, R-rel készített ábra.
Az operációs rendszerek megoszlása a szuperszámítógépeken. Egyszerű, R-rel készített ábra.
(Forrás: Wikimedia commons / HeWhoMowedTheLawn)
Egy nyelvész számára érdekes új paradigma nyílt az adatok tudományával. Az adatok elemzése a nyelvi adatok esetében a szintaktikai elemzésnek feleltethető meg (ezt hívják parsingnak). Az igazán nagy mennyiségű adat kezelése új távlatokat nyit meg, habár a „web mint korpusz” koncepciót sokan kritizálják, annyi bizonyos, hogy sokkal több adatot gyűjthetünk a neten – ami meghaladja az eddigi korpuszok méretét, és ez bizonyos technikai problémákat is felvet –, melyek megoldására az adatok tudománya kész receptekkel szolgálhat.
Habár eddig az adatok prezentálása mostohagyereke volt számítógépes nyelvészetnek, és a korpusznyelvészek sem jeleskedtek benne, most már van kitől tanulnunk, elvégre a legtöbb kutató közpénzből fizetett állami alkalmazott, és elvileg a köz javára ügyködik. Nekik érdemes érthető formában bemutatni a laikusok számára is, mivel is foglalkoznak (nem beszélve arról, hogy egy jó prezentálás segíti a megértést, a tudományos kommunikációt, és ha a módszert az üzleti világban is felhasználják, akkor a döntéselőkészítést is).
Korpusznyelvészet – a nyelvészeti adatok tudománya
A nyelvészet mindig is a nyelvi adatokon alapult, habár az adatok gyűjtésének és feldolgozásának módjainaknincs egységes metodológiája. A legrégebbi és legbevettebb módszer az, amikor a tudós saját nyelvi intuícióját használja. Ezzel nincs semmi baj, hiszen egy nyelv egy adott kompetens beszélője elvileg el tudja dönteni, mely konstrukciók helyesek, illetve helytelenek. Ám ez a módszer nem lehet elégséges alapja egy nyelv leírásának, különösen a „határesetek” körében. Habár elvileg végtelen számú mondata lehet egy adott nyelvnek, és elvileg képes egy kompetens beszélő ezek megértésére, a gyakorlat az mutatja, hogy ez a használat bizonyos faktorok miatt változik (területileg, életkor, társadalmi helyzet stb. szerint). A korpusznyelvészet erre a problémára ad választ, és habár használói főleg a statisztikai megközelítés hívei, a különböző generatív iskolák követői is egyre inkább az adatok felé fordulnak (nem is akármilyen eredménnyel, gondoljunk pl Haegeman kutatásaira vagy Norvin Richards Uttering Trees munkájára).
A korpuszkészítés hagyománya beleillik az adat tudomány praktikáiba, nem csak mi tanulhatunk tehát az adat tudósoktól, hanem mi is segítségükre lehetünk az adatok beszerzése terén, miképp lehet korpuszuk reprezentatív és miképp elemezhetik azt.
'Big data' és nyelvészet á la Google
A Google hatalmas adatmennyiséggel foglalkozik naponta, ennek nagy része szöveges fájl, és ahogy egyre több és több ember kapcsolódik a világhálóra, úgy egyre több és több nyelven generálódik tartalom, amivel valamit kezdenie kell a keresőóriásnak. Az adatok megosztott (több tárhelyen történő) tárolására saját adatbáziskezelő rendszert fejlesztett ki a cég, melynek a Bigtable nevet adta (technikai kérdésekben járatosabb olvasók itt olvashatnak róla bővebben) az adatok kezelésére és lekérdezésére pedig a kifejlesztette a MapReduce programozási modellt (melyről itt olvashat az érdeklődő olvasó).
(Forrás: Wikimedia commons / Schutz)
Nyelvészeti (főleg szövegfeldolgozási) feladatokra gyakran alkalmazzák a fenti technikákat. A Bigtable elosztott rendszere megbízhatóan tárolja a temérdek adatot, a MapReduce algoritmusok pedig lehetővé teszik az adatok hatékony és gyors feldolgozását. A map feladata, hogy az elosztott tárakon köztes kulcs–érték párokat generáljon, amit a reduce függvény fűz össze egy koherens válasszá. Tulajdonképpen a módszer lehetővé teszi, hogy a hatalmas adatmennyiséget „feldarabolva” elemezzünk (apró részproblémákra bontsuk az elemzést), és végül összegezzük a darabokat. Így az eddigi korpuszok méretét nagyságrendekkel meghaladó adatmennyiséget elemezhetünk.
A korábbi korpuszok 10,000 és 10,000,000 elemet tartalmaztak, addig a Google n-gram korpusz 24GB tömörítve (Norvig szerint). Ekkora adatmennyiség viszont érdekes dolgokat produkálhat. A Google Translate mögötti technológiát bemutató írás szerint hatalmas mennyiségű dokumentumot felhasználva készítettek n-gramokat egy-egy nyelvre (maximum 5-gramokig elmenve). Egy nyelv modelljét tulajdonképpen ezen n-gramok gyakorisága adja, amit a mapreduce modellt felhasználva számítanak ki: a fordítási feladat így nem más, mint egy nyelv modelljében megtalálni e legvalószínűbb megfelelést, a leggyakoribb n-szekvenciát. Az A nyelvben a B nyelv hasonló gyakorisági szekvenciájára cserélünk. Meglepő egy nyelvész számára, de ez a megközelítés működik! Persze nem százszázalékos, de érthető és tájékozódásra alkalmas fordításokat produkál a rendszer.
Norvig Natural Language Corpus Data írása (online is elérhető, ille a Beautiful Data kötetben is olvasható) is meghökkentő első olvasatra egy nyelvésznek. A „Google korpusz” használatával a szószegmentáció problémájához nem kell még bi-grammokat sem használni, mivel elég sok adat áll rendelkezésre, hogy nagy hatékonysággal megoldható legyen. Az egyszerű szógyakoriság, ha kellően nagy korpuszon alapul, a helyesírás-ellenőrzőkben is eredményesen használható.
Keseregjünk, hogy nekünk már nincs semmi dolgunk? Nem! Amire rávilágít ez a megközelítés, az nem más, mint a használat elégtelen ismerete. Egyrészt a számítógép-analógiát el kell felejtenünk, az elme nem számítógép, az ember nem így dolgozza fel az adatokat (vagy legalábbis még csak egy tárhelyünk van). Még több adatra van szükségünk! Meg kell vizsgálnunk, mire ad választ az adatok elemzése, és mire nem. Miért működik jól a szegmentáció és a helyesírás-ellenőrzés és miért csak megközelítőleg a gépi fordítás? Több adatra van szükségünk, vagy más eszközökre? Hogy értelmezzük, elemezzük az adatokat?
Látod? Nem? Akkor mutatom!
Az információgrafika (infographics) zászlóshajója a New York Times laborja (mely minden bizonnyal a legismertebb vizualizációs műhely) sokat tett azért, hogy a szép és használható infografikát meg- és elismertesse. Ez természetes igényünk, hisz az ember alapvetően vizuális lény. Az interakciódizájn művelői a kezdeti pionírkorszak után immár elfogadott és egyenrangú partnerei a különböző alkalmazások fejlesztőinek, mivel nem csak az számít, hogy egy szoftver (vagy akár egy fizikai termék) mit tud, hanem az is, hogy hogyan lehet kezelni.
Ugyanez a helyzet a tudományos eredményekkel. Nem elég csak produkálni egy szógyakorisági táblát, vagy megvizsgálni a magyar szórend relatív gyakoriságát, valahogy el kell mondanunk, mit is jelent ez.

(Forrás: Wikimedia commons / Paulsmarsden)
Az adatok tudománya ebben még gyerekcipőben jár. Habár egyre több remek kezdeményezést látunk, még nem terjedtek el részben technikai okok miatt (a html5 szabvány elterjedése ezen segíteni fog), részben pedig azért mert a jó ábrázolás „művészi hajlamokat” is feltételez. Azonban nagyszerű eszközök vannak már a kezünkben, csak meg kell tanulnunk használni őket.
Összegzés
Az adatok tudomány új eszközöket ad a (számítógépes) nyelvészek kezébe, de egyben új kihívások elé is állítja őket. Itt csak azzal próbálkoztam, hogy bemutassam, mit tanulhatunk ettől a szép területtől, miben segíthet nekünk, és miben tehetünk hozzá valamit mi magunk. A következő részben sorra vesszük, milyen eszközökkel érdemes megismerkednünk.
További kapcsolódó cikkek a Számítógépes nyelvészet c. blogról
Az adatok tudománya és a nyelvtudomány - olvasnivaló
Az adatok megmagyarázhatatlan természete
@Cikk:
" a nyelvi adatok megmutatják, hogyan használjuk a nyelvet, az adatok tudománya pedig segíthet meglátni az összefüggéseket. Az adatok tudományának pedig segíthetünk „köztes tagokat” biztosítani az adatok jobb megértéséhez."
Nagyon tetszik ez a cikk, bár régi, még nem olvastam eddig..
Kizárólag számítógépes nyelv feldolgozással foglalkozik, mégis megerősít abban hogy szerintem forrás adatok nem csupán írott szövegek lehetnek a nyelvészek számára.
Ha csak a népdalokra gondolunk, és tegyük fel, hogy még nem fedezték fel az írásbeliséget. Amíg átadják az új generációknak ezt a típusú tudást, információs adatokat adnak át az időben későbbi embereknek..
-Nem véletlenül nevezik adat közlőknek a népdalok, balladák, sőt néptáncok előadóit, akik előadását különböző technikai eszközökkel és leírás segítségével mentik meg a modern tudósok, és művészek..
-Ha pl. az ősnyelv kutatás során speciális (módosult és bővült) adathalmazoknak tekinthetjük a mai nyelveket, és egy idő skálán visszatekintve a fejlettségnek megfelelő tipikus pontokhoz megfelelő szituációkat, valószínűsíthető környezetet rendelünk hozzá, a megfelelő, az oda illő szavakat és összefüggéseket is feltételezhetjük (nemrégen még léteztek ősi kultúrák, amik mintául szolgálhatnak) olyan hanganyaggal módosítva, ami már valószínűleg az adott ősi időben létezhetett..