
A Google a veszélyeztetett nyelvekért
A Google új szolgáltatást indított el: weboldalán a veszélyeztetett nyelvek dokumentálásához nyújt segítséget. De vajon a megadott keretek tényleg dokumentálásra csábítanak, vagy az is lehet, hogy elriasztják a felhasználókat?
A Google új szolgáltatása, az Endangered Languages Project (Veszélyeztetett nyelvek projekt) egyszerre videómegosztó, közösségi oldal és nyelvtanulást támogató oktatási segédlet. Az oldalon videókat, térképeket és más dokumentumokat lehet megosztani. Arra bátorítják a résztvevőket, hogy készítsenek felvételeket a nyelvek még élő beszélőivel, osszák meg ezeket, segítsék egymást a nyelv megtanulásában. A projektet az Alliance for Lingustic Diversity (Szövetség a nyelvi sokszínűségért) támogatja, mely a világ legjelentősebb, a nyelvi dokumentációval és a veszélyeztetett nyelvek megőrzésével foglalkozó kutatóintézeteit tömöríti.
A projekt okairól és céljairól külön videó szól. Ebből kiderül, hogy míg ma körülbelül hétezer nyelvet beszélnek a Földön, a jóslatok szerint ezek fele nem éri meg a századfordulót. Amikor egy nyelv utolsó beszélője meghal, elvesztjük azokat az évszázados hagyományokat és tudást, mely segített nekünk önazonosságunk megtalálásában. A nyelvvesztés gyakran elnyomás és igazságtalanság következménye. A közösségek számára a nyelv megőrzése a kulturális azonosságtudatuk, értékeik és örökségük helyreállításával egyenlő.
A Google megbízható szervezetekkel működik együtt annak érdekében, hogy segítsen nekik megállítani a nyelvek kihalását. A Veszélyeztetett nyelvek projekt olyan online felület, melyet ezen nyelvek beszélői számára, illetve azoknak terveztek, akiknek szenvedélyük a nyelvek megőrzése. Az oldal a legátfogóbb adatokat közli, fel lehet rá tölteni videókat, hanganyagokat és más dokumentumokat, megoszthatjuk rajta tudásunkat és tapasztalatainkat. A videó szerint ez csak a kezdet... az azonban nem világos, mi jöhet még.
Külön ki kell emelnünk, hogy a felület az angol mellett hat jelentős nyelven, spanyolul, oroszul, kínaiul, franciául, németül és portugálul is használható. Ennek köszönhetően a világ szinte bármelyik táján használható: a világ nagy részén éppen ezek a nyelvek szorítják ki a helyi nyelveket. Ugyanakkor sajnálatos hátrány, hogy csak a felület van lefordítva, a nyelvekre vonatkozó alapvető információk például már nem. Sőt, a nyelvek elnevezései sem érhetőek el: hiába keresünk rá az orosz felületen a ханты (hanti) szóra, releváns találatot nem kapunk (annál több irrelevánsat!).
Sajnos az oldalon nem lehet – vagy mi legalábbis nem találtuk meg, miként lehet – annak alapján keresni, hogy mely nyelvhez töltöttek már fel anyagokat, és mennyit. Kétségtelen, hogy később ez kevésbé lesz fontos szempont, de az oldal indulásánál fontos lenne – de később is hasznos lehet látni, mennyire aktívak az egyes projektek.
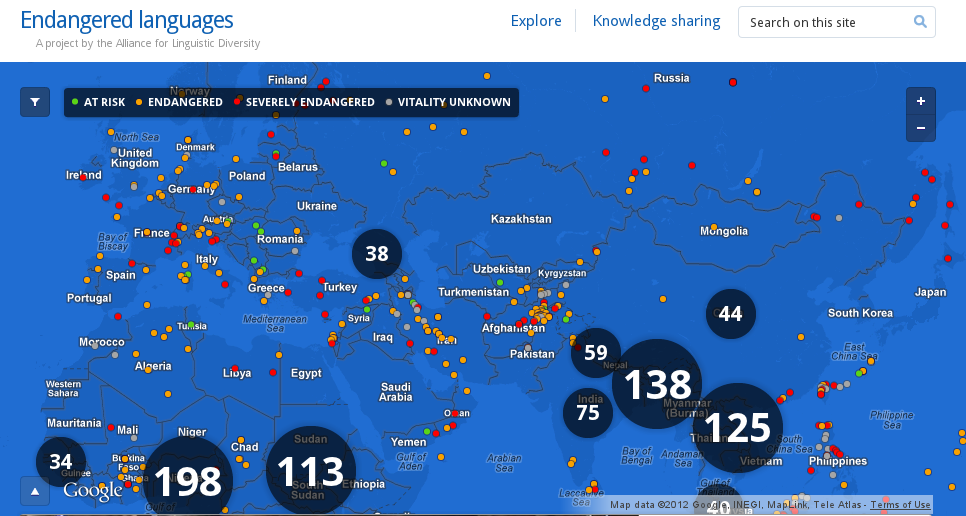
Mivel az oldal nemrég indult, sok anyagot még nem találhatunk. Ellenben érdemes megnézni, hogy milyen kereteket találunk, pontosabban milyen nyelvek dokumentálására van lehetőség. Az uráli nyelvekre rákeresve 35 nyelvből álló listát kapunk: a lista ennél is hosszabb, mivel a felsorolásban bizonyos nyelvek többször is szerepelnek. Még kevésbé érthető, miért pont ezek a nyelvek vannak felsorolva.
Az például feltétlenül támogatandó, hogy a különböző számi (lapp) nyelvek külön-külön vannak felsorolva: akkalai, déli, északi, inari, kildini, kolta (skolt), lulei, pitei, teri, umei. Csakhogy például a hanti egyetlen nyelvként szerepel, holott az északi és a keleti nyelvjárások egyáltalán nem érthetőek kölcsönösen – a legcélszerűbb lenne teljesen külön kezelni az obdorszki, a suriskari, a szinjai, a tegi, kazimi és serkáli, a szurguti és a vahi-vaszjugáni nyelvjárást. Az alábbi videó az egyetlen anyag, mely a hantiknál megtalálható: az adatközlő orosz nyelvű szövegében közli is, hogy suriskari nyelvjárásban beszél. A hanti szöveg 1:12-nél kezdődik: először a számneveket halljuk egytől tízig (először lassan, majd gyorsan), majd egy történetet, illetve egy önéletrajzi elbeszélést. (A szövegek lejegyzése, tartalma nem található meg a videó mellett, így jelen formájában az anyag nem segítheti a nyelv dokumentálását, megőrzését, újjáélesztését.)
Időnként az elnevezés okoz meglepetést: a vót például Vod néven szerepel, holott a szakirodalomban inkább a Votic, esetleg Vadja elnevezést szokás használni. Érdekes kavarodást figyelhetünk meg a nyenyec esetében: külön oldala van Nenets néven, a tundrai változatának Tundra Yurak, erdei változatának Forest Yurak néven. (A kettőt egyébként érdemes külön kezelni, hiszen ezek is kölcsönösen érthetetlenek.) Az már csak hab a tortán, hogy az oldalon szereplő térképek szerint az erdei nyenyecet Kalifornia és Arizona határán, a tundrait pedig ugyanitt, illetve Kanada északi területein beszélik...
Időnként érthetetlen, egyes nyelvek miért maradnak ki a veszélyeztetettek köréből. Így például szerepel a projektben az erza, a moksa, a nyugati (hegyi) és keleti (mezei) mari, az udmurt és a komi-permják is, de a hozzájuk rendkívül hasonló helyzetben levő komi-zürjén nem. (Az már csak apróság, hogy a komi-permjákok elnevezései között több alakban is szerepel a zürjén terminus is, mely ugyan összefoglalóan jelentheti a komi-permjákokat és a komi-zürjéneket is, de elsősorban az utóbbiakat jelöli, gyakran éppen az előbbiekkel való szembeállítás érdekében. A jazvai komi viszont egyszerűen Yazva néven szerepel – a térkép itt is meglepetést okoz, elsősorban azért, mert nem sikerült megállapítani, milyen területet ábrázol: az azonban valószerűtlen, hogy a valódi nyelvterületet.
Meglepő az is, hogy míg például a kvénnek van külön oldala, addig a csángónak nincs – ez talán arra vezethető vissza, hogy míg a kvént kezdik önálló nyelvnek tekinteni, addig a csángót szeretik inkább magyar nyelvjárásként kezelni. Ugyanakkor a nyelvi helyzetük nagyon hasonló, és bizony nem ártana, ha a csángó alaposan dokumentálva lenne. Addig is azzal vigasztalódhatunk, hogy míg a kvénről szóló információk között azt olvashatjuk, hogy Svédországban, a Tornio völgyében beszélik, addig a projekt oldalán a térkép magabiztosan Norvégia belsejében jelöli a nyelvterületet.
Hasonló furcsaságokkal nem csak az uráli nyelvek körében találkozhatunk. A szláv nyelvekre rákeresve például öt nyelvet találunk: ebből három a szorb, mely szerepel felső-szorbként, alsó-szorbként és egyszerűen szorbként is – utóbbi esetben ismét igencsak eltájolva a térképen. Ezeken kívül szerepel a kasub és a burgenlandi horvát, ám nem szerepel például a ruszin, a sziléziai viszont germán nyelvként van besorolva, ami igen kínos tévedés!. Az újlatin nyelveket kutatva nem találjuk a balkáni újlatin nyelveket, a szárdot, a korzikait vagy az okcitánt. Ugyanakkor a romani (cigány) nyelvekre rákeresve a listában találjuk a ladint, a makedo-románt és az istro-románt...
Összefoglalóan tehát megállapíthatjuk, hogy a Google kezdeményezése igen hasznos, de a mögötte álló nagy tekintélyű szervezetektől függetlenül nagyon összecsapottnak, szakmailag megalapozatlannak tűnik. Sajnos ez nem egyszerűen a tudományos kérdés: a téves besorolások akár el is vehetik a potenciális felhasználók kedvét attól, hogy használják az oldalt. (Gondoljuk meg, hány székely használná szívesen az oldalt, ha a székely mint román nyelvjárás szerepelne.) Leginkább tehát abban reménykedhetünk, hogy ez tényleg csak a kezdet, és a folytatás valamivel meggyőzőbb lesz!
@LvT: Igen, való igaz, a cikkben illett volna kitérni a hazai kisebbségi nyelvekre is...
@LvT: Amíg ilyen listákban hiba van, hát kit érdekel... baj legalábbis nem lesz belőle... de amikor a gyakorlatban, ráadásul az érintetteknek kell szembesülniük ezzel...
> Időnként az elnevezés okoz meglepetést: a vót például Vod néven szerepel, holott a szakirodalomban inkább a Votic, esetleg Vadja elnevezést szokás használni.
Úgy nézem, alapvetően a Linguist List LL-MAP-jét dolgozhatták fel (amely pedig a SIL-féle ISO 639-3 finomítása), vö. „Vod” [1], „Nenets” vs. „Forest Yurak” [3]. A „Finnish, Kven”már a SIL-nél/Ethnologue-ban külön entitás [4].
Igaz ez sem ad magyarázatot a „Rusyn” [5] és a „Csángó” [6] hiányára. A veszélyeztetettség indikátora lehet esetleges.
[1] llmap.org/languages/vot.html
[2] llmap.org/languages/yrk.html
[3] llmap.org/languages/yrk-for.html
[4] www.ethnologue.com/show_language.asp?code=fkv
[5] llmap.org/languages/rue.html
[6] llmap.org/languages/hun-csa.html
Magyarországra vonatkoztatva a "vlach romani" (oláhcigány) van jelenleg veszélyeztetettként feltüntetve, holott ez a hazai cigányok által használt leginkább stabil nyelvválozat. A beás pl. még "belcigány" viszonylatban is elnyomott a romani dialektusokkal szemben.
Biztosan van lehetőség valamilyen módon jelezni nekik ezeket a tévedéseket, hogy javítsák ki. A Google-nak egészen jó támogatási háttere van, és a fórumokon is viszonylag hamar reagálnak, ha több felhasználó jelzi a problémát.