
Egy kép többet mond ezer szónál?
Az automatikus tartalomelemzéssel percek alatt több szöveget tudunk analizálni, mint amit egész életünkben képesek lennénk elolvasni. De hogyan lehet összefoglalni egy ilyen elemzés eredményeit? Bónusz: mókás és tanulságos szófelhők 444-től 888-ig.
A fenti kérdésre keressük a választ a május 25-én NLP meetupon, mely témája az adatvizualizáció. Az érdeklődők megtudhatják, hogyan érdemes szófelhőket készíteni, és a Rákosi-éra politikai dokumentumain keresztül a névelemfelismeréssel segített kapcsolatháló elemzésébe is betekinthetnek. A rendezvény ingyenes, de a részvétel előzetes regisztrációhoz kötött az esemény oldalán.
A szófelhők cukik, akkor mi a baj velük?

A fenti szófelhő a Precognox munkatársai Skype-on folytatott üzenetváltásainak leggyakoribb szavait mutatja. Szép, színes, formájával utal Heidy-re, a Skype mókus emotikonjára, ami a leggyakrabban használt eleme ennek a korpusznak. Egy másik változatában a készítők azt szerették volna kihangsúlyozni, hogy a hálózatelemzés eszköztárát gyakran alkalmazzák, ezért készítettek egy erre utaló betűtípust is.
Mindenkit biztosíthatunk, remek móka ilyen szófelhőket gyártani. Azonban nagyon nehéz értelmezni amit látunk. A szavak színesek, de színük nem utal semmire, azt az algoritmus véletlenszerűen választotta ki. A szavak pozíciója annak köszönhető, hogy az algoritmus igyekszik minél jobban kitölteni a rendelkezésére álló teret, ami lehet akár egy forma (ahogy az első ábránál) akár egy szokványos téglalap (a második ábra esetében). Az egyetlen tényleges információ mindkét ábrán a szavak egymáshoz viszonyított mérete, ami előfordulási gyakoriságukra utal. Ez bizony nagyon zavaró lehet, hiszen megnehezíti az ábra értelmezését (l. erről bővebben Pinker klasszikus tanulmányát).
A csetes szövegeket tartalmazó korpusz megjelenítésével akad még egy probléma, nem igazán tudjuk megmondani, hogy az adatközlők közül egy-egy szó kire jellemzőbb inkább (sőt, szándékosan nem is különítettük ezt el). Nézzünk inkább egy másik példát! 2017. április 1. és 2017. április 14. között keletkezett szövegeket gyűjtöttünk, az index, a 444, a 888 és az origo oldalakról, melyek CEU, a civil törvény, vagy Soros György címkék valamelyikével lettek megjelölve. Az cikkek minden szavát kisbetűsre alakítottuk, névelemfelismerés segítségével a többelemű neveket (pl. Soros György, Orbán Viktor) összevontuk, minden szót lecseréltünk szótövére, végül pedig kiszűrtük az ún. stopszavakat (kötőszavak és nagyon gyakori szavak). Így gyakorisági táblákat készítettünk az egyes oldalakra, ezekből készítettünk szófelhőket, melyeken minden szó ugyanolyan színű.
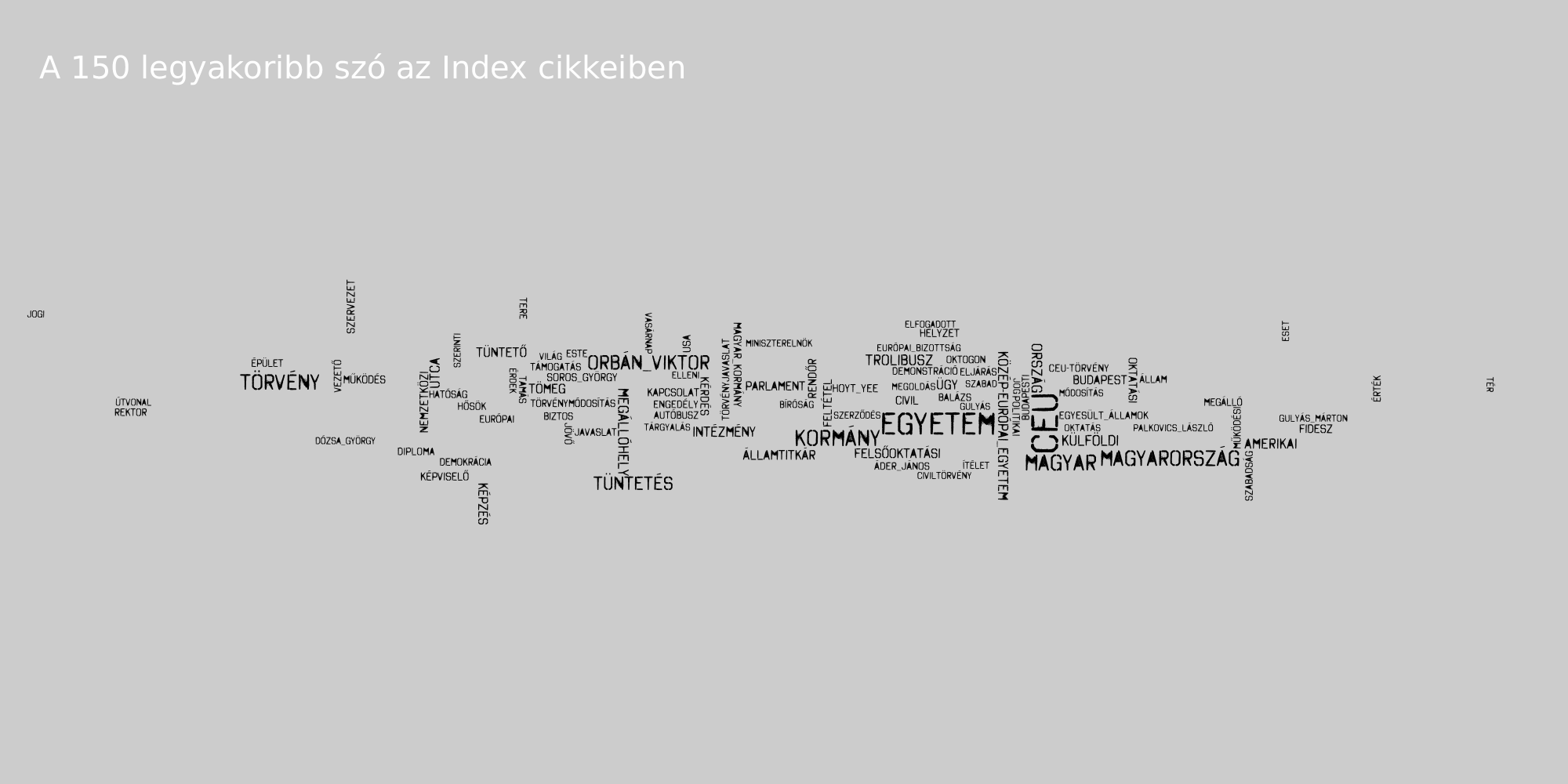
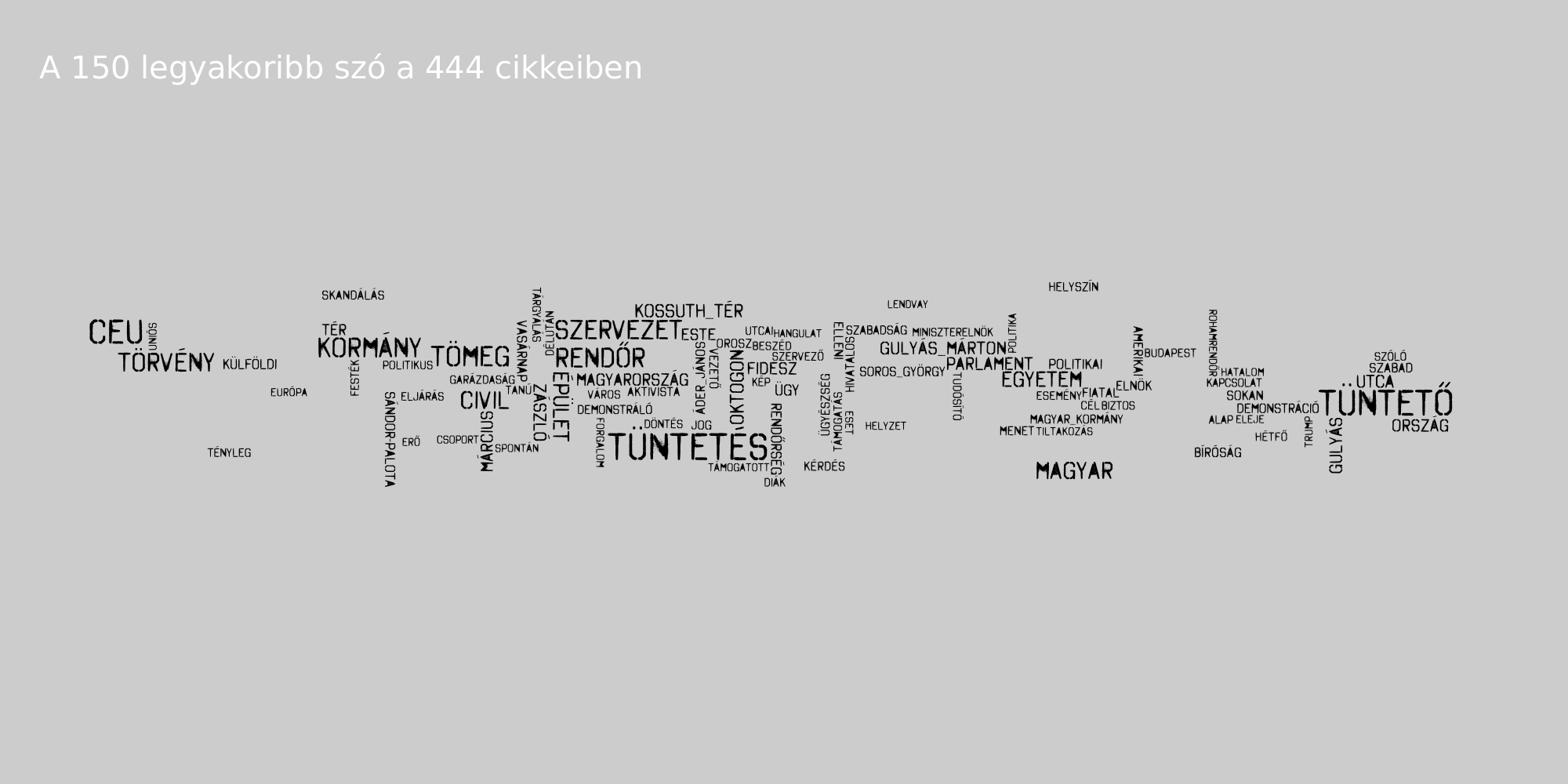
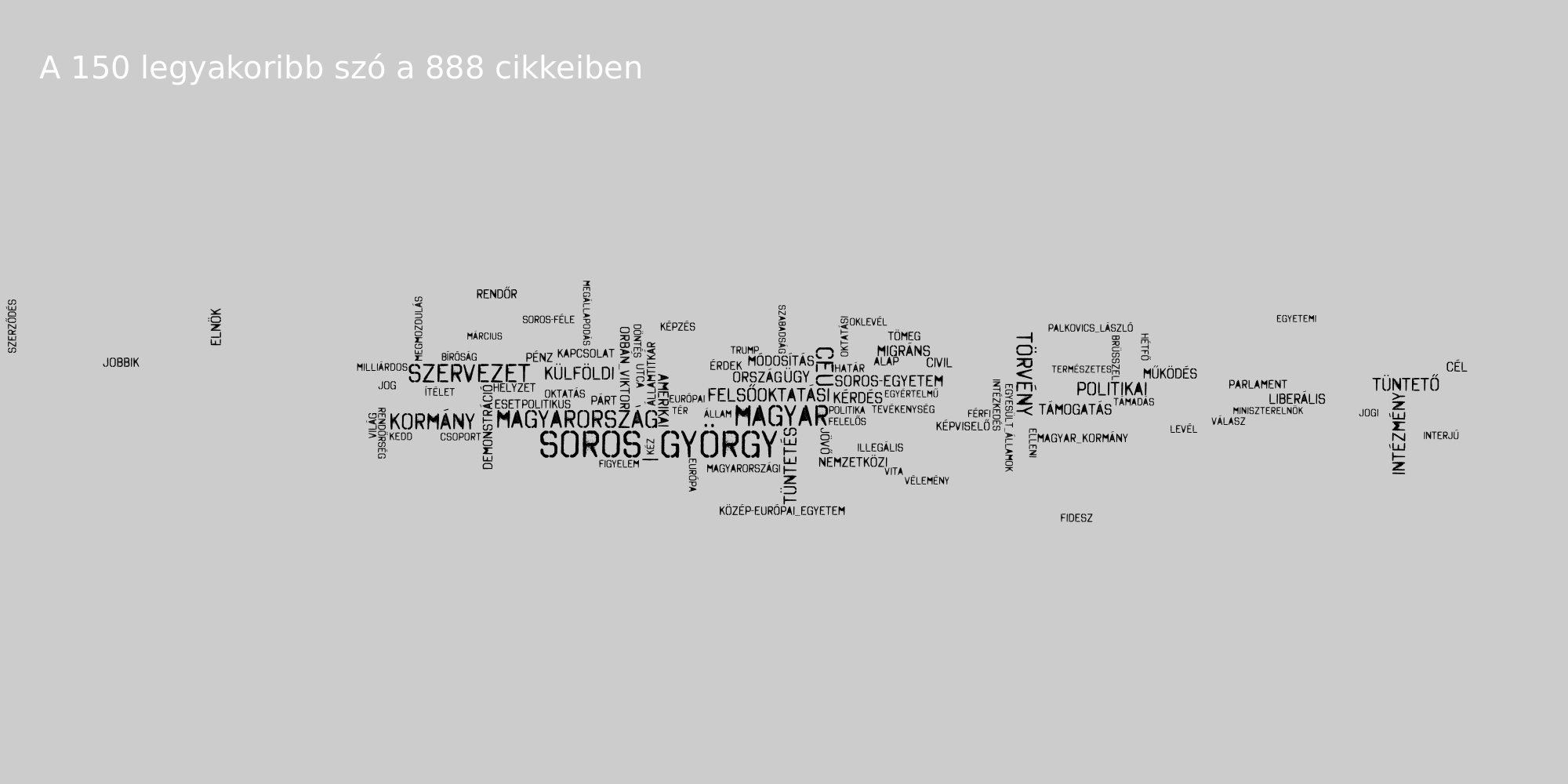
Ez a megközelítés már lehetővé teszi, hogy lássuk az egyes oldalak által kedvelt szavak gyakoriságát, azonban kicsit nehézkes összehasonlítani egy-egy oldal eltérő nyelvhasználatát. Erre két bevett módszer van. A Conway szófelhők azt szemléltetik, hogy a korpusz egyes szövegeiben melyik használja többet az adott szót, illetve mely szavak gyakorisága közös. Mi ábránkhoz összevontuk a 444 és az index szöveget, illetve a 888 és az origo cikkeit.

Ezzel a megközelítéssel az az egyik probléma, hogy ha az egyik része a korpusznak 101 alkalommal említi például a CEU-t, a másik pedig 100-szor, akkor a győzteshez sorolja, pedig a különbség elenyésző. Ezen lehet segíteni, ha a különbség mértékét is jelöljük valahogy, ekkor viszont a közös szavak halmaza hihetetlenül nagy lesz. Ábránkkal is így jártunk, ezért nem jelenítettük meg végül gyakoriságban kicsit eltérő elemeket.
A másik megoldás azt megvizsgálni, hogy mennyire tér el a korpusz egy részében a szavak gyakorisága az egész korpuszban tapasztalható gyakoriságtól, ezt nevezik keyness-nek, azaz kb. kulcsságnak. Így már értelmezhetőbb eredményt kapunk. Az alábbi ábrán már színeket is használtuk, ezek jelölik, melyik oldalon jelentős kulcsszó a megjelenített szó. A szavak nagysága nem gyakoriságot, hanem “keyness score-t” jelöl, amit úgy fordíthatunk, hogy mennyire jellemző a korpusz adott részre az adott szó használata.

Túl a szófelhőkön
Ha jól használjuk a szófelhőket, akkor átfogó képet adhat a vizsgált korpuszról, de annak belső részleteiről nem árul el sokat. Nem árt tudni, hogy bizonyos szavakat a vizsgált szöveg elején, közepén, vagy végén használnak. Igazán izgalmas lehet az is, hogy milyen környezetben található az adott szó, ezt nevezik a korpusznyelvészek konkordanciának és így néz ki a gyakorlatban Orbán Viktor országértékelő beszédeinek szótövezett változatán az Európa szóra kapott konkordancia az AntConc programban:
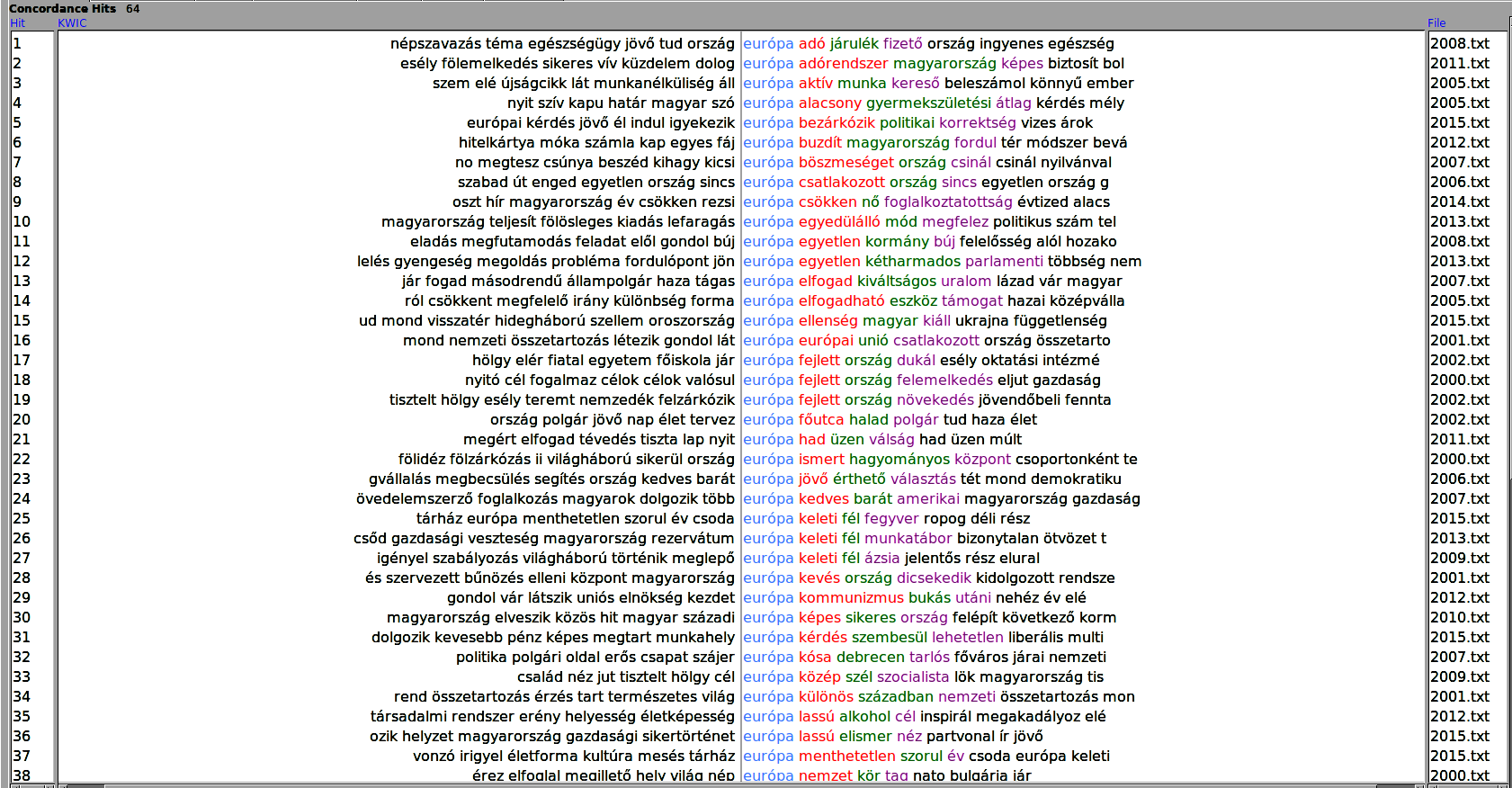
Konkordancia plotnak hívjuk annak ábrázolását, hogy egy-egy kifejezés az adott szövegen belül hol (és hányszor) fordul elő. Az alábbi példán több kifejezés előfordulását is mutatjuk az Orbán Viktor évértékelő beszédeit tartalmazó korpuszunkból.

Ki, kivel?
Egy jól előkészített szövegben automatikus névelemfelismerést szoktunk végezni, amit ha szerencsénk van kiegészít még az idiómák (gyakran együtt használt, de írásban különálló szavak) kinyerése is, amivel tovább finomítható az elemzés. Szerencsére ma már magyar nyelvre is könnyen készíthető névelemfelismerő, ezért nem jelenthet gondot megszámolni, hogy adott szövegegységen belül (mondat, bekezdés, vagy dokumentum) hányszor szerepel együtt egy-egy névelem. Ebből felépíthetünk egy hálózatot, mint amilyet korábbi, a magyarországi migrációval foglalkozó cikkeket elemző írásunkhoz készült, melyen a gyakran együtt emlegetett intézményeket ábrázoltuk:
Akik szeretnének többet is megtudni a szövegek adatvizualizációjáról, azokat szeretettel várják a rendezők a május 25-én, csütörtökön 18:30-kor kezdődő NLP Meetupra a Háló Közösségi és Kulturális Központba (Budapest, Semmelweis utca 4.) Az este során Gulyás Attila és Boros István (MTA TK “Lendület” RECENS Kutatócsoport) a Rákosi-éra politikai szövegeiből kinyert kapcsolathálókról tart előadás, Varjú Zoltán (Precognox) pedig a szófelhőkről és egyéb szövegvizualizációs technikákról fog beszélni. A rendezvény ingyenes, de előzetes regisztrációhoz kötött az esemény oldalán.